CompTIA DY0-001 Practice Test 2026
Updated On : 12-Jun-2026Prepare smarter and boost your chances of success with our CompTIA DY0-001 practice test 2026. These CompTIA DataAI Exam test questions helps you assess your knowledge, pinpoint strengths, and target areas for improvement. Surveys and user data from multiple platforms show that individuals who use DY0-001 practice exam are 40–50% more likely to pass on their first attempt.
Start practicing today and take the fast track to becoming CompTIA DY0-001 certified.
1890 already prepared
89 Questions
CompTIA DataAI Exam
4.8/5.0

The following graphic shows the results of an unsupervised, machine-learning clustering
model:
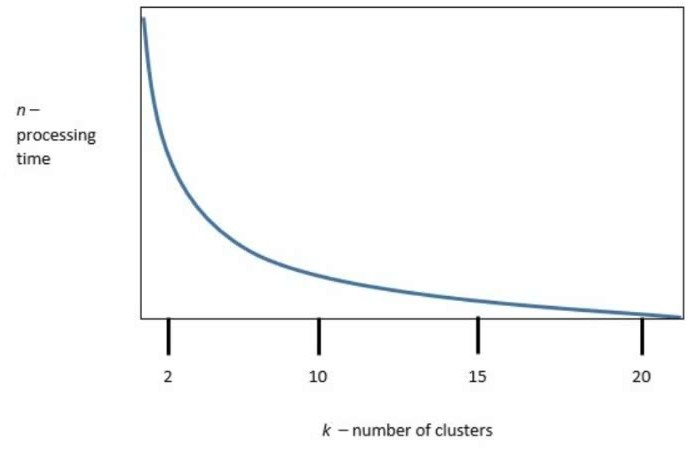 k is the number of clusters, and n is the processing time required to run the model. Which
of the following is the best value of k to optimize both accuracy and processing
requirements?
k is the number of clusters, and n is the processing time required to run the model. Which
of the following is the best value of k to optimize both accuracy and processing
requirements?
A. 2
B. 10
C. 15
D. 20
Explanation:
In unsupervised clustering, especially with algorithms like K-Means, choosing the optimal number of clusters (k) is a trade-off between model accuracy and computational efficiency. Based on standard techniques like the Elbow Method and Silhouette Score, the best value of k is typically where:
Accuracy gains begin to plateau, meaning adding more clusters doesn’t significantly improve separation.
Processing time (n) remains reasonable and doesn’t spike unnecessarily.
If the graphic shows that k = 10 yields strong clustering performance with moderate processing time, it represents the sweet spot—where the model is both effective and efficient.
📚 Reference:
GeeksforGeeks – Optimal K in K-Means Clustering
❌ Why Other Options Are Less Optimal
A. k = 2:
Too coarse—likely underfits the data and misses meaningful subgroups.
C. k = 15 and D. k = 20:
May slightly improve accuracy but at the cost of significantly higher processing time and risk of overfitting or fragmented clusters.
Given the equation:
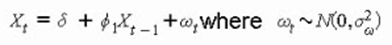
Xt = + 1Xt1 + t,where t N(0, ²)
Which of the following time series models best represents this process?
A. ARIMA(1,1,1)
B. ARMA(1,1)
C. SARIMA(1,1,1) × (1,1,1)1
D. AR(1)
Step 1: Breakdown the Equation
This equation defines the value of the time series at time t (X_t) as being composed of three parts:
A constant term (δ).
A term that depends on the value of the series at the previous time step (φ₁X_{t-1}).
A random error term (ε_t), which is normally distributed with a mean of zero and a constant variance.
Step 2: Match the Equation to a Model Type
This structure is the classic definition of an Autoregressive model of order 1, abbreviated as AR(1).
Autoregressive (AR):
The model uses past values of the series itself to predict the current value.
Order 1: The model only uses the immediately preceding value (X_{t-1}). The highest lag in the model is 1.
Step 3: Eliminate the Other Options
Now, let's see why the other models do not fit this equation:
A. ARIMA(1,1,1): This model has three components:
AR(1): An autoregressive part of order 1 (this part matches).
I(1): An integration (differencing) part of order 1. This means the model is built on the changes in the data (e.g., X_t - X_{t-1}) rather than the raw data itself. Our equation has no differencing.
MA(1): A moving average part of order 1. This would mean the model also uses past error terms (e.g., θ₁ε_{t-1}). Our equation has no moving average component.
B. ARMA(1,1):
This model has two components:
AR(1): An autoregressive part of order 1 (this part matches).
MA(1): A moving average part of order 1. Again, our equation has no moving average component (θ₁ε_{t-1} is missing).
C. SARIMA(1,1,1) × (1,1,1)s:
This is a highly complex model that includes:
Non-Seasonal ARIMA(1,1,1): Has the same issues as option A (includes unwanted differencing and moving average parts).
Seasonal Components: It also includes seasonal autoregressive, differencing, and moving average terms. Our equation shows no seasonal elements.
Conclusion
The given equation X_t = δ + φ₁X_{t-1} + ε_t contains only an autoregressive component of order 1 and a constant term. It lacks any differencing (the "I" component), moving average (the "MA" component), or seasonal elements.
Reference:
This question falls under Domain 4.0: Data Analysis of the CompTIA Data+ (DA0-001) exam objectives, specifically the skill of understanding and applying different time series models and their components.
| Page 1 out of 9 Pages |
CompTIA DataAI Exam Practice Questions
CompTIA DataAI DY0-001 Official Exam Blueprint Weight & Our Practice Questions
| CompTIA DataAI DY0-001 Domain | Official Exam Weight | Our Practice Questions |
|---|---|---|
| Mathematics and Statistics | 17% | 15 |
| Our Practice Questions Covers Subtopics: Probability, Descriptive statistics, Inferential statistics, Hypothesis testing, Regression analysis, Correlation, Distributions, Bayesian statistics, Linear algebra, Calculus concepts, Statistical modeling, Confidence intervals, Data normalization, Sampling techniques, Statistical significance | ||
| Modeling, Analysis, and Outcomes | 24% | 24 |
| Our Practice Questions Covers Subtopics: Predictive modeling, Data analysis, Feature engineering, Model evaluation, Outcome interpretation, Data visualization, Classification models, Regression models, Clustering, Dimensionality reduction, Business outcomes, KPI analysis, Analytical workflows, Data storytelling, Reporting and dashboards | ||
| Machine Learning | 24% | 19 |
| Our Practice Questions Covers Subtopics: Supervised learning, Unsupervised learning, Reinforcement learning, Neural networks, Deep learning, Natural language processing (NLP), Computer vision, Model training, Model tuning, Bias and variance, Overfitting and underfitting, Decision trees, Random forests, Support vector machines, AI model evaluation | ||
| Operations and Processes | 22% | 20 |
| Our Practice Questions Covers Subtopics: MLOps, Data pipelines, Data governance, Data preparation, Data engineering, Model deployment, CI/CD workflows, Cloud AI services, Data security, Automation, Workflow orchestration, Version control, Monitoring and logging, Ethical AI, Compliance and governance | ||
| Specialized Applications of Data Science | 13% | 11 |
| Our Practice Questions Covers Subtopics: Generative AI, Recommendation systems, Time-series forecasting, Fraud detection, AI ethics, Healthcare analytics, Financial modeling, Retail analytics, Robotics, Autonomous systems, Specialized AI applications, Industry-specific AI solutions | ||
Data analytics, governance, and visualization—this exam validates your data skills. This practice test covers DY0-001 objectives: data mining, data profiling, quality control, and reporting. You will work through questions on cleaning datasets, using visualization tools, applying statistical methods, and communicating insights to stakeholders. Each answer includes detailed explanations that reinforce best practices for real-world data projects. By simulating the actual exam experience, it builds your confidence and reveals knowledge gaps before test day. Whether you struggle with data governance or visualization techniques, this test helps you focus your preparation effectively.
Stories of Success
Data concepts are fundamental for analytics roles. Preptia DY0-001 practice questions covered data types, governance, and visualization in a practical way. The questions were clear and aligned with the exam objectives. Passed on my first try!
Andrew Mitchell, Data Analyst | Chicago, IL
Data analytics fundamentals became clearer with Preptia.com practice tests for Data+ (DY0-001). The test questions covered data mining, visualization, and governance topics in a very practical way.
Sofia Petrova | Bulgaria