CompTIA CNX-001 Practice Test 2026
Updated On : 12-Jun-2026Prepare smarter and boost your chances of success with our CompTIA CNX-001 practice test 2026. These CompTIA CloudNetX Exam test questions helps you assess your knowledge, pinpoint strengths, and target areas for improvement. Surveys and user data from multiple platforms show that individuals who use CNX-001 practice exam are 40–50% more likely to pass on their first attempt.
Start practicing today and take the fast track to becoming CompTIA CNX-001 certified.
1840 already prepared
84 Questions
CompTIA CloudNetX Exam
4.8/5.0

A network engineer at an e-commerce organization must improve the following dashboard
due to a performance issue on the website:
(Refer to the image: Website performance monitoring dashboard showing metrics like
network usage, CPU usage, memory usage, and disk usage over time.)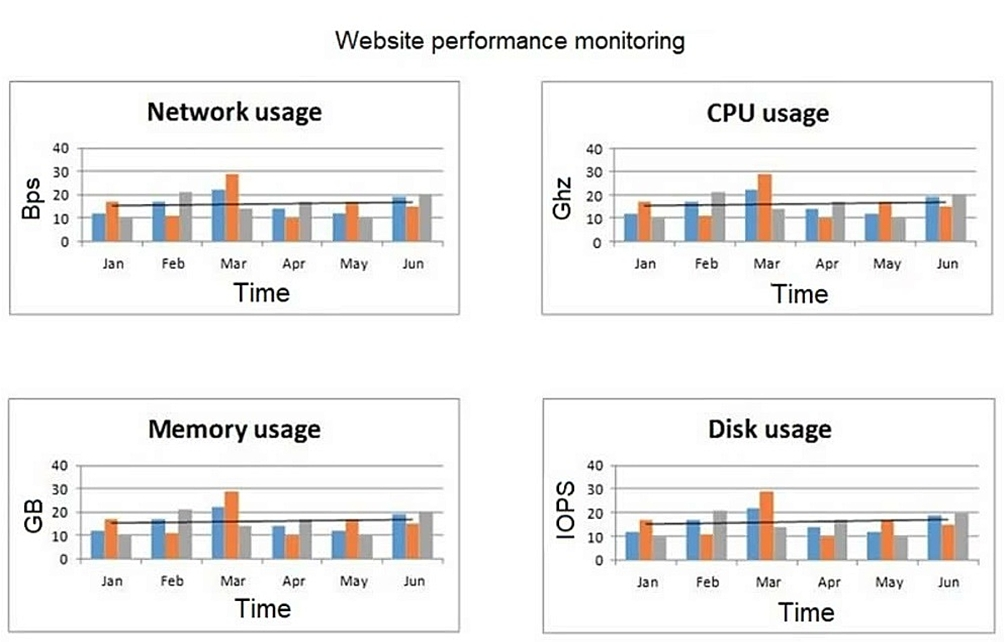
Which of the following is the most useful information to add to the dashboard for the
operations team?
A. 404 errors
B. Concurrent users
C. Number of orders
D. Number of active incidents
Explanation:
When diagnosing a general "performance issue" on a website, correlating system resource metrics (CPU, Memory, Network, Disk) with user load is the most critical piece of information for the operations team.
Root Cause Analysis:
The existing dashboard shows the effect (high resource usage). Concurrent users shows the most likely cause. A spike in concurrent users would logically explain a corresponding spike in resource utilization, leading to slow page loads and a poor user experience. Without this metric, the team cannot determine if high resource usage is expected (due to high traffic) or unexpected (due to an inefficient application or infrastructure problem).
Actionable Data:
This information directly guides the next steps for investigation:
If resource spikes correlate perfectly with user spikes, the solution may be to scale up infrastructure (e.g., add more web servers) to handle the load.
If resources are high while user count is low, it points to a severe application or system problem (e.g., a memory leak, inefficient code, or a misconfigured service) that needs immediate software-level investigation.
Why the other options are less useful for diagnosing performance:
A. 404 errors:
404 errors indicate "page not found" conditions. While important for monitoring site health and user experience, they are primarily related to content availability or configuration errors (e.g., broken links). A large number of 404s might consume some resources, but they are not a primary or direct cause of broad performance issues like slow page rendering or high CPU load across the entire site.
C. Number of orders:
This is a business metric, not an infrastructure performance metric. While a sales surge might cause a rise in traffic, the orders themselves are the result of user activity. The direct technical driver of performance is the number of users generating requests, not the number of transactions that complete successfully. It is less directly correlated to system load than concurrent users.
D. Number of active incidents:
This is an operational metric for tracking the response to problems. Displaying it on a performance dashboard adds no value for diagnosing the root cause of a new performance issue. It tells you that problems exist but provides no technical data to explain why.
In summary:
For an operations team tasked with solving a performance issue, the single most useful additional metric to correlate with system resources is Concurrent Users. It provides the essential context needed to distinguish between expected high load and anomalous system behavior.
New devices were deployed on a network and need to be hardened.
INSTRUCTIONS
Use the drop-down menus to define the appliance-hardening techniques that provide the
mostsecure solution.
If at any time you would like to bring back the initial state of the simulation, please click the
Reset All button.?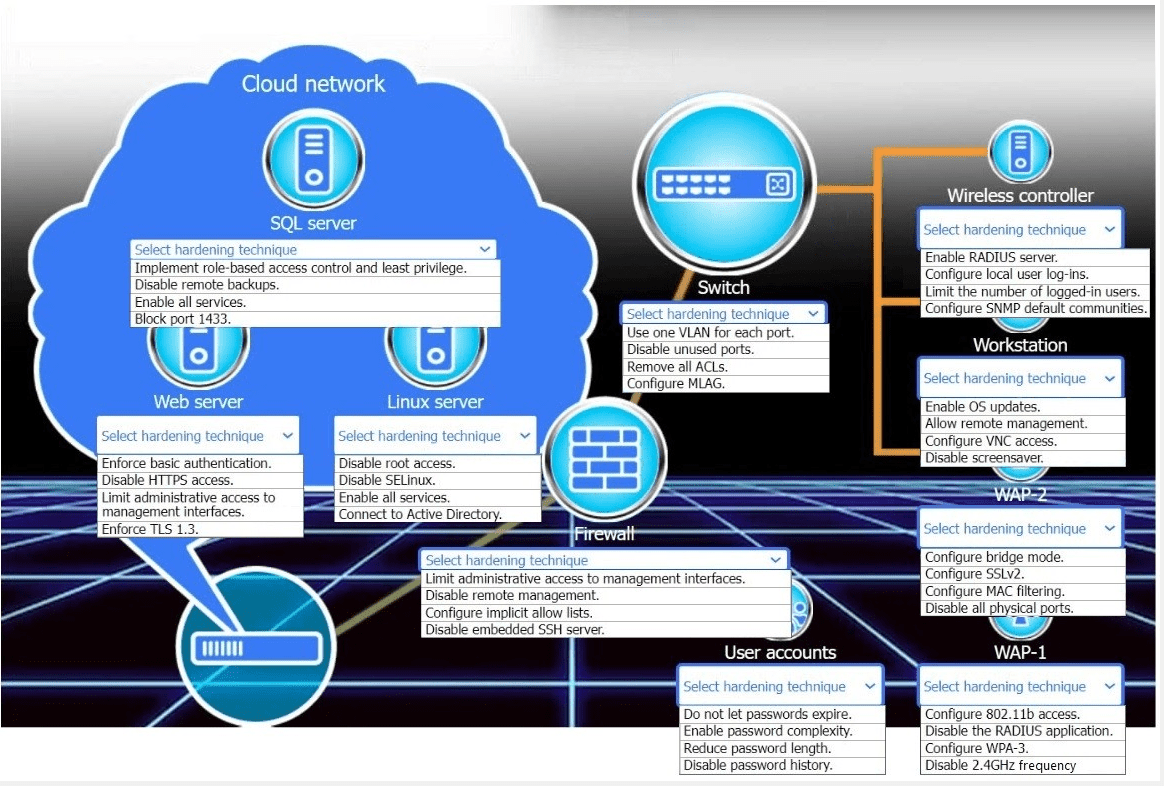
A network administrator is troubleshooting a user's workstation that is unable to connect to the company network. The results of ipconfig and arp -a are shown. The user’s workstation:

Has an IP address of 10.21.12.8
Has subnet mask 255.255.255.0
Default gateway is 10.21.12.254
ARP table shows 10.21.12.8 mapped to 1A-21-11-31-74-4C (a different MAC address than the local adapter)
A. Asynchronous routing
B. IP address conflict
C. DHCP server down
D. Broadcast storm
Explanation:
The evidence from the ipconfig /all and arp -a outputs strongly indicates an IP address conflict on the network.
Let's break down the key clues:
The Workstation's Identity:
The ipconfig /all command shows the workstation has:
IP Address: 10.21.12.8
Physical (MAC) Address: IA-21-11-33-44-5A
The ARP Table Anomaly:
The arp -a command displays the workstation's own ARP cache.
In this cache, the IP address 10.21.12.8 (its own IP) is not mapped to its own MAC address (IA-21-11-33-44-5A).
Instead, it is mapped to a different MAC address: 1A-21-11-31-74-4C.
This is the definitive symptom of an IP address conflict. Here’s why:
The ARP protocol resolves IP addresses to MAC addresses. When the workstation needs to communicate with itself (a common internal process) or when it receives traffic for its own IP, it looks in its ARP table.
The presence of its own IP address (10.21.12.8) mapped to a foreign MAC address (1A-21-11-31-74-4C) means another device on the same network segment is also using the IP address 10.21.12.8.
The workstation has likely received an ARP reply or broadcast from this other device claiming that IP address, causing its ARP cache to be updated incorrectly. This disrupts the workstation's ability to manage its own network identity and process incoming traffic correctly, leading to connectivity issues.
Why the Other Options Are Incorrect:
Option A (Asynchronous routing):
This occurs when the path out of a network is different from the path back in, often due to misconfigured routers. The problem here is isolated to a single IP address on a single subnet, and the ARP table provides no evidence of a routing issue. The gateway (10.21.12.254) is present and has a valid MAC in the ARP table.
Option C (DHCP server down):
If the DHCP server were down, the workstation would not have a valid IP address. It would likely have an APIPA address in the 169.254.x.x range. The output shows the workstation does have a valid IP address (10.21.12.8), subnet mask, and default gateway, proving DHCP (or static configuration) was functional.
Option D (Broadcast storm):
A broadcast storm is a network-level event caused by switching loops, where broadcast traffic (like ARP requests) floods the network, crippling all connectivity. The provided outputs show a stable and populated ARP table, which would not be possible during a storm. The problem is specific to one IP-MAC mapping, not a widespread network failure.
Conclusion:
The ARP table showing the workstation's own IP address mapped to another device's MAC address is a classic and clear sign of an IP address conflict. The administrator needs to find the device with the MAC address 1A-21-11-31-74-4C and change its IP address or configure the DHCP server to prevent it from handing out 10.21.12.8 again.
| Page 1 out of 9 Pages |
CompTIA CloudNetX Exam Practice Questions
CompTIA CloudNetX CNX-001 Official Exam Blueprints And Our Practice Questions
| CompTIA CloudNetX CNX-001 Domain | Official Exam Weight | Our Practice Questions |
|---|---|---|
| Network Architecture Design | 31% | 28 |
| Our Practice Questions Covers Subtopics: Hybrid cloud architecture, Enterprise network design, IPv4 and IPv6 addressing, Routing and switching, SD-WAN, SASE architecture, Network segmentation, Wireless networking, Connectivity solutions, Load balancing, High availability, Disaster recovery architecture, Cloud networking, DNS and DHCP, BGP and OSPF, Virtual networking, Data center networking | ||
| Network Security | 28% | 29 |
| Our Practice Questions Covers Subtopics: Zero Trust architecture, Identity and access management (IAM), Microsegmentation, Firewalls, VPN technologies, Network access control, Authentication protocols, Encryption, Secure protocols, Threat mitigation, Security policies, Security frameworks, Cloud security, Risk management, Compliance requirements, Security monitoring, Secure connectivity | ||
| Network Operations, Monitoring, and Performance | 16% | 15 |
| Our Practice Questions Covers Subtopics: Network monitoring, Performance optimization, Network maintenance, Automation and scripting, Observability, SIEM integration, Log analysis, Capacity planning, Traffic analysis, SLA monitoring, Network analytics, SNMP, Telemetry, Operational management, Cloud monitoring tools | ||
| Network Troubleshooting | 25% | 12 |
| Our Practice Questions Covers Subtopics: Troubleshooting methodology, Connectivity issues, Routing problems, Wireless troubleshooting, DNS issues, Latency analysis, Packet captures, Network diagnostics, Performance bottlenecks, Hardware failures, Cloud connectivity issues, Configuration troubleshooting, Monitoring alerts, Root cause analysis | ||
Cloud networking and hybrid infrastructure expertise is rare—and this exam proves it. This practice test targets CNX-001 objectives: network architecture, security, automation, and troubleshooting across multi-cloud environments. You will face questions on SD-WAN, zero-trust security, cloud connectivity, and network monitoring tools. Each scenario tests your ability to design and troubleshoot complex cloud networks. The detailed explanations clarify why certain solutions work better in specific architectures. By revealing gaps in your cloud networking knowledge, this test helps you focus study time where it matters most—preparing you for this advanced certification challenge.
Stories of Success
Cloud networking is a specialized skill, and this beta exam required focused preparation. Preptia CNX-001 practice test helped me master SDN, cloud connectivity, and network virtualization. I felt ready for every question type and passed easily. Great for anyone pursuing cloud networking!
Rachel Stevens, Cloud Network Engineer | San Francisco, CA
Advanced cloud networking topics were easier to understand using Preptia.com practice materials for CloudNetX (CNX-001). The scenario-based questions helped reinforce hybrid cloud connectivity concepts.
Oliver Scott | Australia