CompTIA 220-1202 Practice Test 2026
Updated On : 17-Jul-2026Prepare smarter and boost your chances of success with our CompTIA 220-1202 practice test 2026. These CompTIA A+ Core 2 (2026 Exam Update) test questions helps you assess your knowledge, pinpoint strengths, and target areas for improvement. Surveys and user data from multiple platforms show that individuals who use 220-1202 practice exam are 40–50% more likely to pass on their first attempt.
Start practicing today and take the fast track to becoming CompTIA 220-1202 certified.
13250 already prepared
325 Questions
CompTIA A+ Core 2 (2026 Exam Update)
4.8/5.0

Topic 1 : Multiple Choice Questions
A technician inspects the following workstation configuration: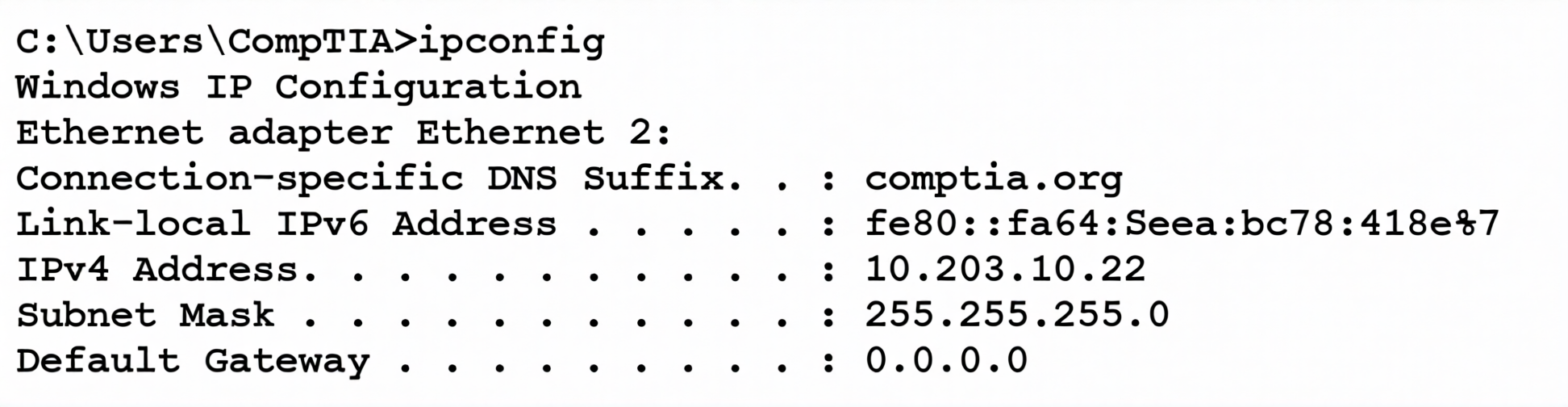
The workstation is unable to open any external websites. The browser displays an error message that says that the site cannot be reached.
A. The wrong DNS suffix is assigned.
B. The workstation IP address is incorrect.
C. The default gateway is not set.
D. The subnet mask is incorrect
Explanation:
Why this answer is correct:
The ipconfig output clearly shows the Default Gateway is listed as 0.0.0.0. In IPv4 networking, a default gateway of all zeros indicates that no gateway (router) has been configured or assigned. The default gateway is responsible for routing traffic from the local subnet to external networks, including the internet. If this value is missing or set to 0.0.0.0, the workstation has no path to reach any device outside its own local network (10.203.10.x). Therefore, even if DNS were working perfectly, the computer would not know how to send the packets to the web server, resulting in the "site cannot be reached" error.
Why the other options are incorrect:
A. The wrong DNS suffix is assigned
The DNS suffix (comptia.org) is used for appending to unqualified hostnames. While a misconfigured DNS server could cause website resolution failures, the immediate problem is the lack of a gateway. Even with the correct DNS, the packets have nowhere to go. Furthermore, the error "site cannot be reached" is often a generic connectivity error before DNS resolution is even attempted.
B. The workstation IP address is incorrect
The IP address 10.203.10.22 with a mask of 255.255.255.0 is a perfectly valid private IP address. There is nothing inherently incorrect about it. The issue is the lack of a route (gateway) to the internet, not the IP itself.
D. The subnet mask is incorrect
The subnet mask 255.255.255.0 is the standard default mask for a Class C /24 network and is correct for the 10.203.10.22 address in many common configurations. If it were wrong, the computer might have trouble communicating even with local devices, but the specific symptom of failing to reach external sites points directly to the missing gateway.
CompTIA A+ Objective Reference:
This question falls under Domain 2.0: Networking. It aligns with objectives related to troubleshooting wired and wireless networks using the ipconfig command and interpreting its output to identify configuration issues like a missing default gateway.
| Page 1 out of 33 Pages |
CompTIA A+ Core 2 (2026 Exam Update) Practice Questions
CompTIA A+ Core 2 (220-1202) Exam Blueprint & Question Bank
| CompTIA 220-1202 Domain | Official Exam Weight | Our Practice Questions |
|---|---|---|
| 1.0 Operating Systems | 28% | 90 |
| Our Practice Questions Cover Subtopics: Windows OS features and tools, macOS and Linux fundamentals, OS installation and upgrades, command-line tools, cloud-based productivity tools, Microsoft Windows networking | ||
| 2.0 Security | 28% | 119 |
| Our Practice Questions Cover Subtopics: Physical and logical security, malware types and removal, wireless security protocols, social engineering attacks, authentication methods, workstation and mobile security, data destruction, browser security | ||
| 3.0 Software Troubleshooting | 23% | 60 |
| Our Practice Questions Cover Subtopics: Windows OS troubleshooting, PC security issue resolution, mobile OS and application troubleshooting, malware removal best practices | ||
| 4.0 Operational Procedures | 21% | 56 |
| Our Practice Questions Cover Subtopics: Documentation and change management, backup and recovery methods, safety procedures, environmental controls, licensing and policies, communication techniques, scripting basics, remote access, AI fundamentals | ||
What Our Community Says
After passing 220-1201, I needed the same quality prep for 220-1202. Preptia.com delivered again with 220-1202 practice exam covering operating systems, security, and troubleshooting. The real exam felt like another practice session. Two passes, one trusted resource!
Amanda Foster, Desktop Support Specialist | Nashville, TN
Operating systems and troubleshooting topics became easier to understand while preparing for CompTIA A+ Core 2 using Preptia.com. The realistic 220-1202 practice exam made exam preparation simple and efficient.
Emily Carter | United Kingdom