CompTIA DS0-001 Practice Test 2026
Updated On : 29-Jun-2026Prepare smarter and boost your chances of success with our CompTIA DS0-001 practice test 2026. These CompTIA DataSys+ Certification test questions helps you assess your knowledge, pinpoint strengths, and target areas for improvement. Surveys and user data from multiple platforms show that individuals who use DS0-001 practice exam are 40–50% more likely to pass on their first attempt.
Start practicing today and take the fast track to becoming CompTIA DS0-001 certified.
11200 already prepared
120 Questions
CompTIA DataSys+ Certification
4.8/5.0

A DBA is reviewing the following logs to determine the current data backup plan for a
primary data server:
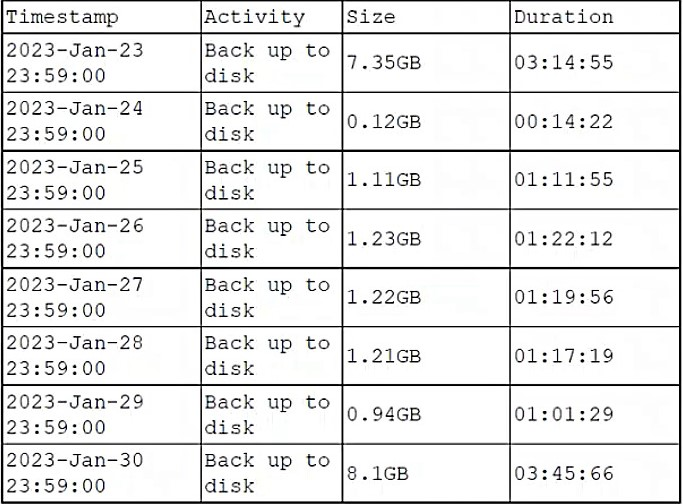
Which of the followingbestdescribes this backup plan?
A. Monthly full, daily differential
B. Daily differential
C. Daily full
D. Weekly full, daily incremental
Explanation:
The backup logs show a clear pattern: large backups on January 23rd (7.35GB) and January 30th (8.1GB), occurring exactly one week apart. Between these dates, the daily backups are significantly smaller, ranging from 0.12GB to 1.23GB. This pattern is characteristic of a weekly full backup with daily incremental backups.
A full backup captures the entire database, which explains the large file sizes on the 23rd and 30th. Incremental backups only capture data changes since the most recent backup (whether full or incremental), resulting in much smaller backup sizes and faster backup times. The small, varying sizes reflect the daily volume of changes in the database.
Why other options are incorrect:
A. Monthly full, daily differential:
Incorrect. A monthly full backup would show large backups approximately 30 days apart, not weekly. Additionally, differential backups capture all changes since the last full backup, so they would grow progressively larger each day until the next full backup—a pattern not seen here, where sizes remain relatively small and consistent.
B. Daily differential:
Incorrect. This would mean no full backups at all, which is impractical for recovery. Also, differential backups require a baseline full backup to function.
C. Daily full:
Incorrect. Daily full backups would show consistently large file sizes (like 7GB+) every day, not the pattern of one large backup followed by six small ones.
Reference:
CompTIA DataSys+ DS0-001 Objective 5.2: "Given a scenario, implement and test backup and restoration procedures." This includes understanding backup types (full, incremental, differential) and identifying backup strategies from logs.
A database administrator is creating a table, which will contain customer data, for an online
business. Which of the following SQL syntaxes should the administrator use to create an
object?

A. Option A
B. Option B
C. Option C
D. Option D
Explanation:
Option D shows the correct SQL syntax for creating a table. The proper CREATE TABLE statement requires:
The keywords CREATE TABLE
The table name (CUSTOMER)
Column definitions enclosed in parentheses with proper data types
Each column definition separated by commas
Option D follows this syntax exactly: CREATE TABLE CUSTOMER (ID INT, NAME VARCHAR(100), AGE INT)
Why other options are incorrect:
A. Option A:
Missing the table name after CREATE TABLE. Every table must have a name.
B. Option B:Uses CREATE CUSTOMER instead of CREATE TABLE. The keyword TABLE is required.
C. Option C:
Incorrect syntax with parentheses placed incorrectly and missing commas between column definitions.
Reference:
CompTIA DataSys+ DS0-001 Objective 3.1: "Given a scenario, create and modify database objects using scripts and SQL." This includes understanding proper CREATE TABLE syntax with column definitions and data types.
| Page 1 out of 12 Pages |
CompTIA DataSys+ Certification Practice Questions
CompTIA DataSys+ DS0-001 Official Exam Blueprint Weight
| CompTIA DataSys+ DS0-001 Domain | Official Exam Weight | |
|---|---|---|
| Database Fundamentals | 24% | |
| Subtopics: Relational databases, Non-relational databases, SQL code development, DDL, DML, TCL, ACID principles, Stored procedures, Views, Scripting methods, Python, PowerShell, Command-line scripting, ORM tools, SQL validation | ||
| Database Deployment | 16% | |
| Subtopics: Planning and design, Requirements gathering, Database architecture, Data dictionaries, Entity relationship diagrams, Schema validation, Stress testing, Version control, Database connectivity, Installation, Configuration, Provisioning, Scalability validation | ||
| Database Management and Maintenance | 25% | |
| Subtopics: Monitoring and reporting, System alerts, Performance metrics, Transaction logs, Resource utilization, Query optimization, Patch management, Capacity planning, Performance tuning, SOPs, Compliance documentation, Data modification, Redundancy management, Views, Materialized views | ||
| Data and Database Security | 23% | |
| Subtopics: Encryption, Data masking, Data destruction, Data loss prevention, Retention policies, GDPR, PCI DSS, Authentication, Authorization, Access controls, Password policies, Identity management, Physical controls, Firewalls, Port security, SQL injection, DoS attacks, Phishing, Ransomware, Brute-force attacks | ||
| Business Continuity | 12% | |
| Subtopics: Backup and recovery, Disaster recovery planning, Replication strategies, Failover processes, High availability, Clustering, Load balancing, System redundancy, Risk assessment, Business impact analysis, Risk mitigation, Continuity testing | ||
Database administration requires both theory and hands-on skills—and this exam tests both. This practice test covers DS0-001 objectives: database design, security, backup recovery, monitoring, and troubleshooting across multiple platforms. You will face questions on normalization, indexing, transaction management, and performance optimization. Each scenario tests your ability to apply DBA concepts to real database environments. The detailed explanations clarify why certain approaches work better for specific workloads. By identifying gaps in your knowledge of security or disaster recovery, this test helps you focus your study where it matters most—preparing you for certification success.
Stories of Success
Database systems require knowledge of administration, security, and troubleshooting. Preptia DS0-001 practice exam covered SQL, backup strategies, and performance tuning in depth. I felt completely prepared and passed on my first attempt. Great resource for data professionals!
Jessica Barnes, Database Administrator | Dallas, TX
Learning data systems and database fundamentals was more efficient with Preptia.com practice exams for DataSys+ (DS0-001). The materials explained storage, architecture, and system management concepts clearly.
Victor Ramirez | Chile