Free CompTIA DS0-001 Practice Questions 2026 - Page 3

A database is configured to use undo management with temporary undo enabled. AnUPDATEis run on the table. Which of the following describes where the undo is stored?
A. In the system global area
B. In the undo
C. In the SYSAUX
D. In the temporary
Explanation:
When temp_undo_enabled = TRUE is configured, undo records for operations on temporary tables are stored in a temporary tablespace instead of the traditional undo tablespace .
For an UPDATE operation on a table with temporary undo enabled:
The undo data is stored in the temporary tablespace
This significantly reduces redo log generation (often to near zero)
The temporary undo segments exist only for the duration of the transaction or session
Why other options are incorrect:
A. In the system global area:
Incorrect. The SGA contains the buffer cache where undo blocks are temporarily cached before being written to disk, but this is not the permanent storage location .
B. In the undo:
Incorrect. This refers to the traditional undo tablespace. When temporary undo is enabled, undo for temporary objects is explicitly separated from the permanent undo tablespace .
C. In the SYSAUX:
Incorrect. SYSAUX is an auxiliary tablespace to SYSTEM, used for database tools and options, not for undo storage .
Reference:
CompTIA DataSys+ DS0-001 Objective 3.3: "Explain the purpose of database maintenance and monitoring." This includes understanding undo management and the purpose of temporary undo for temporary objects.
Which of the following services is responsible for assigning, managing, and reclaiming IP addresses on a TCP/IP-based network?
A. DNS
B. DHCP
C. LDAP
D. ISMTP
Explanation:
Dynamic Host Configuration Protocol (DHCP) is the network service responsible for automatically assigning IP addresses to devices on a network, managing those address assignments, and reclaiming them when they are no longer needed or when leases expire. This automation eliminates the need for manual IP configuration and helps prevent address conflicts.
Why other options are incorrect:
A. DNS:
Incorrect. Domain Name System (DNS) translates domain names (like www.example.com) to IP addresses, but does not assign or manage IP addresses.
C. LDAP:
Incorrect. Lightweight Directory Access Protocol (LDAP) is used for accessing and maintaining directory information services, such as user authentication and organizational data.
D. ISMTP:
Incorrect. This appears to be a misspelling of SMTP (Simple Mail Transfer Protocol), which is used for email transmission, not IP address management.
Reference:
CompTIA DataSys+ DS0-001 Objective 2.1: "Given a scenario, deploy and configure databases in various environments." This includes understanding network infrastructure components like DHCP that support database connectivity.
A database administrator is migrating the information in a legacy table to a newer table.
Both tables contain the same columns, and some of the data may overlap.
Which of the following SQL commands should the administrator use to ensure that records
from the two tables are not duplicated?
A. UNION
B. JOIN
C. IINTERSECT
D. CROSS JOIN
Explanation:
The UNION operator is the correct choice for combining records from two tables while eliminating duplicates. When migrating data from a legacy table to a newer table with potential overlap, UNION will:
Combine all rows from both tables
Automatically remove duplicate rows (identical records appearing in both tables)
Return a distinct result set containing unique records only
The administrator can use a query like:
sql
SELECT * FROM legacy_table
UNION
SELECT * FROM new_table;
This ensures the final set contains each record only once, preventing duplication during migration.
Why other options are incorrect:
B. JOIN:
Incorrect. JOIN combines columns horizontally based on a matching condition, not rows vertically. It would not prevent record duplication; it would instead create new rows with combined columns.
C. INTERSECT:
Incorrect. INTERSECT returns only the rows that exist in both tables (the overlapping data), which is the opposite of what the administrator needs for a complete migration.
D. CROSS JOIN:
Incorrect. CROSS JOIN produces a Cartesian product, matching every row from the first table with every row from the second table, resulting in massive duplication (rows = rows_in_table1 × rows_in_table2).
Reference:
CompTIA DataSys+ DS0-001 Objective 3.2: "Compare and contrast different data movement strategies." This includes understanding SQL set operators like UNION for combining data sets without duplication.
A database administrator needs to ensure continuous availability of a database in case the server fails. Which of the following should the administrator implement to ensure high availability of the database?
A. ETL
B. Replication
C. Database dumping
D. Backup and restore
Explanation:
Replication is the process of copying and maintaining database objects (like tables) across multiple servers in real-time or near-real-time. If the primary server fails, a replica server can be promoted or automatically take over, minimizing downtime and ensuring continuous availability. This makes replication a core high availability (HA) strategy.
Why other options are incorrect:
A. ETL:
Incorrect. ETL (Extract, Transform, Load) is used for data integration and movement between systems, typically for data warehousing or migration. It does not provide real-time failover or continuous availability.
C. Database dumping:
Incorrect. Database dumping refers to exporting the database to a file (a logical backup). While useful for backups, it does not provide high availability as restoring from a dump requires significant downtime.
D. Backup and restore:
Incorrect. Backups are essential for disaster recovery but do not ensure continuous availability. Restoring from a backup takes time, during which the database is unavailable.
Reference:
CompTIA DataSys+ DS0-001 Objective 5.3: "Compare and contrast high availability and disaster recovery strategies." This includes understanding replication as a key high availability solution.
Which of the following is a reason to create a stored procedure?
A. To minimize storage space
B. To improve performance
C. To bypass case sensitivity requirements
D. To give control of the query logic to the user
Explanation:
Stored procedures improve performance through several mechanisms:
They are pre-compiled and cached in memory, reducing parsing and compilation overhead with each execution
They reduce network traffic by executing multiple operations on the server instead of sending multiple queries
They can leverage execution plans that are reused for subsequent executions
Why other options are incorrect:
A. To minimize storage space:
Incorrect. Stored procedures actually consume storage space in the database. They are not designed to save space but to encapsulate logic and improve performance.
C. To bypass case sensitivity requirements:
Incorrect. Case sensitivity is determined by the database collation settings, not by stored procedures. Stored procedures do not override or bypass these settings.
D. To give control of the query logic to the user:
Incorrect. Stored procedures actually do the opposite—they centralize control with the database administrator or developer, hiding query logic from users and enforcing consistent data access.
Reference:
CompTIA DataSys+ DS0-001 Objective 3.1: "Given a scenario, create and modify database objects using scripts and SQL." This includes understanding the benefits of stored procedures for performance optimization.
Which of the following are the best resources for monitoring potential server issues? (Choose two.)
A. User connections
B. Firewall usage
C. Index usage
D. CPU usage
E. Query execution
F. Memory usage
F. Memory usage
Explanation:
D.CPU usage measures the processing capacity being consumed by the server. When CPU utilization consistently exceeds 80-85%, it indicates the server is under heavy load and may soon become unable to process requests in a timely manner. High CPU usage can lead to query timeouts, connection failures, and overall performance degradation. Monitoring CPU helps administrators identify processing bottlenecks, plan capacity upgrades, and detect runaway processes before they crash the server.
F.Memory usage reflects how much RAM is available for database operations. Databases rely heavily on memory for caching data, storing execution plans, and managing connections. When available memory runs low, the operating system begins paging or swapping data to disk, which is thousands of times slower than RAM access. This causes dramatic performance drops and can lead to database instability, transaction failures, or complete server unresponsiveness. Memory pressure is one of the most common root causes of database performance issues.
Together, these two metrics form the foundation of server health monitoring. They are universally applicable across all database platforms and provide the earliest warnings of potential failures, allowing administrators to take proactive measures before users are affected.
Why other options are incorrect:
A. User connections:
While tracking connections helps with capacity planning, it doesn't directly measure server health. A server could have few connections but still fail due to resource exhaustion.
B. Firewall usage:
This is a security monitoring metric related to network access control, not server performance or stability.
C. Index usage:
This is a query optimization metric that helps improve specific query performance but does not indicate overall server health.
E. Query execution:
Monitoring slow queries helps identify optimization opportunities but is not a primary indicator of potential server failure.
Reference:
CompTIA DataSys+ DS0-001 Objective 3.3: "Explain the purpose of database maintenance and monitoring." This includes monitoring key server resources like CPU and memory to identify potential issues before they cause failures.
Which of the following is a typical instruction that is found on a Linux command-line script and represents a system shell?
A. /bin/bash
B. #/bin/shell
C. >/bin/sh
D. #!/bin/bash
Explanation:
The shebang line #!/bin/bash is the correct and typical instruction found at the beginning of Linux shell scripts. It consists of:
#! (called "shebang" or "hashbang") - a special marker that tells the system to interpret the script using the specified interpreter
/bin/bash - the absolute path to the Bash shell interpreter that should execute the script
When a script containing #!/bin/bash is executed, the operating system loads the Bash shell and passes the script content to it for execution. This ensures the script runs with the correct shell environment regardless of the user's current shell.
Why other options are incorrect:
A. /bin/bash:Incorrect. Without the #! prefix, this is just a file path and does nothing as the first line of a script.
B. #/bin/shell: Incorrect. This is missing the exclamation mark (!) after the hash, and "/shell" is not a standard shell interpreter path.
C. >/bin/sh:
Incorrect. The > symbol is a redirection operator used for output redirection, not for specifying an interpreter. Also, it lacks the required #! prefix.
Reference:
CompTIA DataSys+ DS0-001 Objective 2.3: "Given a scenario, deploy and configure databases in various environments." This includes understanding basic scripting concepts in Linux environments where databases like MySQL or PostgreSQL are commonly deployed.
Which of the following scripts would set the database recovery model for sys.database?
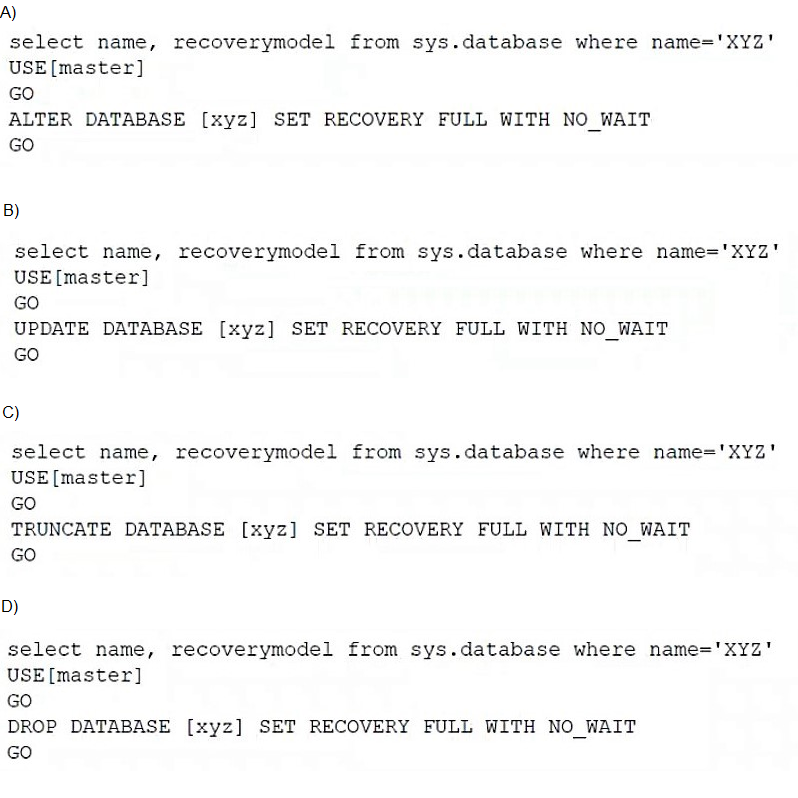
A. Option A
B. Option B
C. Option C
D. Option D
Explanation:
Option A contains the correct T-SQL syntax for changing a database recovery model in Microsoft SQL Server. The proper statement is:
sql
ALTER DATABASE [xyz] SET RECOVERY FULL WITH NO_WAIT
ALTER DATABASE is the correct command to modify database properties
SET RECOVERY FULL changes the recovery model to FULL
WITH NO_WAIT specifies that the statement should fail immediately if it cannot acquire locks without waiting
The script first queries sys.databases to verify the current recovery model, then uses ALTER DATABASE to change it.
Why other options are incorrect:
B. Option B: Incorrect. UPDATE DATABASE is not valid SQL syntax. The UPDATE command is used to modify data in tables, not database properties.
C. Option C: Incorrect. TRUNCATE DATABASE is not valid syntax. TRUNCATE is used to remove all rows from a table, not to modify database settings.
D. Option D: Incorrect. DROP DATABASE would delete the entire database, which is dangerous and not related to changing recovery models. This command removes the database completely.
Reference:
CompTIA DataSys+ DS0-001 Objective 3.1: "Given a scenario, create and modify database objects using scripts and SQL." This includes understanding how to modify database configuration settings like recovery models using proper SQL syntax.
An automated script is using common passwords to gain access to a remote system. Which of the following attacks is being performed?
A. DoS
B. Brute-force
C. SQL injection
D. Phishing
Explanation:
A brute-force attack is an automated trial-and-error method used to obtain access credentials by systematically attempting all possible combinations or, as described here, using common passwords until the correct one is found. The scenario explicitly states an "automated script" is "using common passwords to gain access," which perfectly matches the definition of a brute-force attack (specifically a dictionary variation that uses common passwords instead of every possible combination).
Why other options are incorrect:
A. DoS (Denial of Service):
Incorrect. A DoS attack aims to overwhelm a system with traffic or requests to make it unavailable to users, not to gain unauthorized access through password guessing.
C. SQL injection:
Incorrect. SQL injection involves inserting malicious SQL code into application queries to manipulate the database, not attempting to guess passwords through an automated script.
D. Phishing:
Incorrect. Phishing uses deceptive communications (usually emails) to trick users into revealing sensitive information voluntarily, rather than using automated scripts to guess passwords.
Reference:
CompTIA DataSys+ DS0-001 Objective 4.3: "Given a scenario, identify and apply database security measures." This includes understanding common attack types like brute-force attempts and implementing appropriate defenses such as account lockout policies and strong password requirements.
Which of the following is used to hide data in a database so the data can only be read by a user who has a key?
A. Data security
B. Data masking
C. Data protection
D. Data encryption
Explanation:
Data encryption is the process of converting readable data (plaintext) into an unreadable format (ciphertext) using an algorithm and a key. Only users with the correct decryption key can reverse the process and read the original data. This directly matches the scenario where data can "only be read by a user who has a key."
Why other options are incorrect:
A. Data security:
Incorrect. This is an overly broad term encompassing all measures and controls used to protect data (including encryption, access controls, auditing, etc.), not the specific mechanism described.
B. Data masking:
Incorrect. Data masking (or obfuscation) replaces sensitive data with fictional but realistic data for purposes like testing or training. It is typically irreversible and does not use a key for reading the original data.
C. Data protection:
Incorrect. Similar to data security, this is a broad concept covering various methods (backups, access control, encryption, etc.) to safeguard data from corruption, loss, or unauthorized access.
Reference:
CompTIA DataSys+ DS0-001 Objective 4.1: "Compare and contrast data protection and data privacy concepts." This includes understanding encryption as a key method for protecting data confidentiality.
| Page 3 out of 12 Pages |