Free CompTIA XK0-006 Practice Questions 2026 - Page 4

Troubleshooting
An administrator receives reports that a web service is not responding. The administrator reviews the
following outputs:
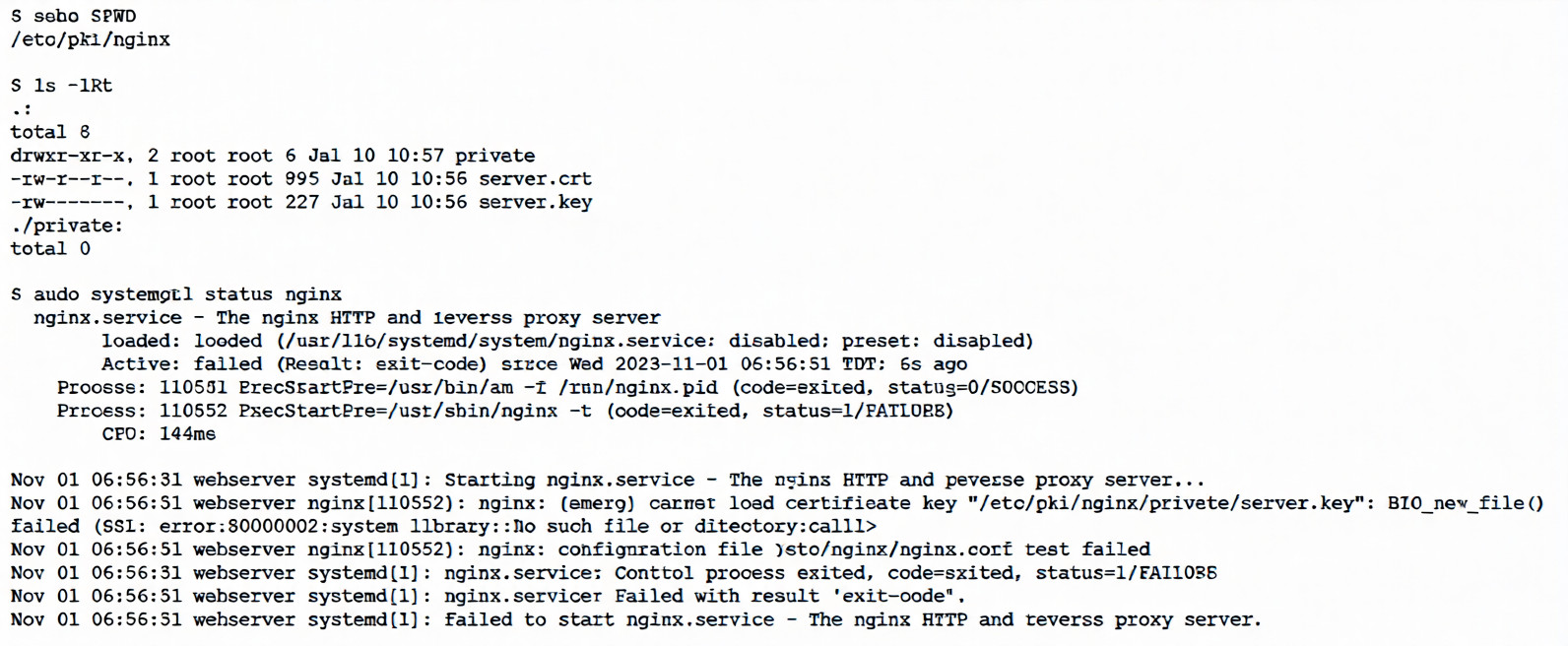
Which of the following is the reason the web service is not responding?
A. The private key needs to be renamed from server.crt to server, key so the service can find it.
B. The private key does not match the public key, and both keys should be replaced.
C. The private key is not in the correct location and needs to be moved to the correct directory.
D. The private key has the incorrect permissions and should be changed to 0755 for the service.
Explanation:
The key error in the logs is:
textnginx: [emerg] cannot load certificate key "/etc/pki/nginx/private/server.key": BIO_new_file() failed (SSL: error:80000002:system library::No such file or directory:calling:fopen('/etc/pki/nginx/private/server.key','r') error:10000080:BIO routines::no such file)
Even though ls -lRt clearly shows the file exists:
text-rw------- 1 root root 227 Jul 10 10:56 server.key
Nginx is reporting it as "No such file or directory" when trying to open it via OpenSSL's BIO_new_file().
This is a classic symptom of permission denied being translated into a misleading "No such file or directory" error by OpenSSL/Nginx.
The file has permissions -rw------- (0600) → readable/writable only by root.
Nginx usually runs as user nginx (or www-data on Debian/Ubuntu), not as root.
Therefore, the nginx process cannot read the private key file → OpenSSL fails to open it → reports "no such file" (a known quirk in older OpenSSL error handling; newer versions often say "Permission denied" more clearly, but the behavior matches many documented cases).
Why the other options are incorrect
The private key needs to be renamed from server.crt to server.key → No, the file is already named server.key, and the config is pointing to it correctly (the error is about reading it, not the name).
The private key does not match the public key, and both keys should be replaced → No, the error occurs before any matching/validation; Nginx can't even load the key file to begin with.
The private key is not in the correct location and needs to be moved → No, ls confirms it's exactly where the config expects: /etc/pki/nginx/private/server.key.
Correct fix (what the admin should do)
Change the permissions so the nginx user can read the key (common secure practice):
sudo chmod 640 /etc/pki/nginx/private/server.key sudo chown root:nginx /etc/pki/nginx/private/server.key # or root:www-data depending on distro640 = owner (root) rw, group r, others none
Group = nginx (or the group nginx runs under)
Then test and restart:
sudo nginx -t
sudo systemctl restart nginx
This resolves the startup failure and allows the web service (Nginx) to respond again.
This is a very common real-world and exam-style troubleshooting scenario for Nginx + SSL in CompTIA Linux+ (XK0-006), especially under security/hardening and service management objectives.
A Linux administrator attempts to log in to a server over SSH as root and receives the following error
message: Permission denied, please try again. The administrator is able to log in to the console of the server
directly with root and confirms the password is correct. The administrator reviews the configuration of the
SSH service and gets the following output:

Based on the above output, which of the following will most likely allow the administrator to log in over SSH
to the server?
A. Log out other user sessions because only one is allowed at a time.
B. Enable PAM and configure the SSH module.
C. Modify the SSH port to use 2222.
D. Use a key to log in as root over SSH.
Explanation:
The SSH configuration shows PermitRootLogin prohibit-password, which specifically disables password authentication for root while allowing key-based authentication. This explains why the administrator can log in at the console (which doesn't use SSH) but gets "Permission denied" when trying to log in over SSH with a password.
Analysis of the SSH configuration:
Port 22 # Standard SSH port - not the issue
PermitRootLogin prohibit-password # ⚠️ KEY ISSUE: Root can ONLY log in with keys
PasswordAuthentication yes # Password auth allowed for regular users
PermitEmptyPassword no # Empty passwords not allowed (sensible)
Use PAM no # PAM disabled (but not the root cause)
MaxSessions 1 # Only one session per connection
MaxAuthTries 3 # 3 authentication attempts before disconnect
What prohibit-password means:
Root cannot authenticate with a password over SSH
Root can authenticate with SSH keys (public/private key pairs)
Regular users can still use passwords (since PasswordAuthentication yes)
This is a security best practice to prevent brute-force attacks on the root account
Why other options are incorrect:
❌ Log out other user sessions because only one is allowed at a time.
MaxSessions 1 limits sessions per connection, not total concurrent logins
This would affect multiple simultaneous connections from the same client
The error is "Permission denied" (authentication failure), not "Too many sessions"
Not related to the authentication failure
❌ Enable PAM and configure the SSH module.
Use PAM no means PAM (Pluggable Authentication Modules) is disabled
While this could affect authentication, it's not the primary issue
The key problem is PermitRootLogin prohibit-password
Even with PAM enabled, root password login would still be prohibited
❌ Modify the SSH port to use 2222.
Port 22 is the standard SSH port and is correctly configured
Changing the port wouldn't fix authentication issues
The administrator can connect (gets to password prompt), so port is reachable
Port change is for security through obscurity, not for fixing authentication
Solution: Set up key-based authentication for root
On the client (as root or with sudo):
# Generate SSH key pair (if you don't have one)
ssh-keygen -t rsa -b 4096 -f ~/.ssh/id_rsa_root
# Copy public key to server
ssh-copy-id -i ~/.ssh/id_rsa_root.pub root@server
# or manually:
cat ~/.ssh/id_rsa_root.pub | ssh root@server "mkdir -p ~/.ssh && cat >> ~/.ssh/authorized_keys"
# Set correct permissions on server
chmod 700 /root/.ssh
chmod 600 /root/.ssh/authorized_keys
Then log in with:
ssh -i ~/.ssh/id_rsa_root root@server
Alternative: Change SSH configuration (less secure)
If key-based authentication isn't feasible, the administrator could modify the SSH config:
# Edit /etc/ssh/sshd_config
PermitRootLogin yes # Allow root login with password (less secure)
# OR
PermitRootLogin without-password # Same as prohibit-password (keys only)
# Then restart SSH
systemctl restart sshd
But this is NOT recommended as it weakens security.
SSH PermitRootLogin Options:
Option Password Auth Key Auth Security Level
yes ✅ ✅ Low
prohibit-password ❌ ✅ High
without-password ❌ ✅ High (same as above)
forced-commands-only ❌ ✅ (with command restriction) Very High
no ❌ ❌ Maximum (root can't SSH at all)
Security Best Practices:
Never allow root password authentication over SSH
Use PermitRootLogin prohibit-password or better, PermitRootLogin no and use sudo
Always use key-based authentication for administrative access
Consider disabling root SSH entirely and using a regular user with sudo
Reference:
OpenSSH configuration file: /etc/ssh/sshd_config
PermitRootLogin controls whether root can log in via SSH
prohibit-password is the modern equivalent of without-password
After changing SSH config, always restart the service: systemctl restart sshd
Always test SSH configuration before disconnecting: sshd -t
Users report that a Linux system is unresponsive and simple commands take too long to complete. The Linux
administrator logs in to the system and sees the following: Output 1:
10:06:29 up 235 day, 19:23, 2 users, load average: 8.71, 8.24, 7.71

Which of the following is the system experiencing?
A. High latency
B. High uptime
C. High CPU load
D. High I/O wait times
Explanation:
The system's unresponsiveness is directly correlated to the extremely high load averages and CPU utilization percentages shown in the outputs.
Load Average Analysis:
Output 1 shows a load average of 8.71, 8.24, 7.71. In a system with 4 CPUs (as indicated in Output 2), a load average above 4.00 means the CPU is fully saturated and processes are actively queuing for execution time. A load of 8.71 means the system is over-capacity by more than 100%.
CPU Utilization Details:
Output 2 shows the CPU breakdown:
%usr (User): 65.88 – More than half of the processing power is being consumed by user-level applications.
%sys (System): 20.54 – A significant portion is consumed by the kernel.
%idle: 0 – The CPU has zero downtime; it is working at 100% capacity.
Result:
When the %idle reaches 0 and the load average exceeds the core count, simple commands become sluggish because they must wait in a long queue for CPU cycles.
Explanation of Incorrect Answers
High latency:
While the user experience feels latent, "latency" in a Linux exam context usually refers specifically to network delay (ICMP/ping times) or disk response times. The primary issue here is local processing resource exhaustion.
High uptime:
Output 1 shows the system has been up for 235 days. While this is a long time, high uptime does not inherently cause a system to be unresponsive unless it has led to an unpatched memory leak or log file bloat, which is not evidenced here.
High I/O wait times:
Output 2 shows an %iowait of 5.65. While there is some disk/network waiting occurring, it is relatively low compared to the 65.88% user load. If I/O wait were the primary cause of unresponsiveness, that number would typically be much higher (e.g., >30%) while the CPU remained mostly idle.
Reference
CompTIA Exam Objective: Domain 5.0 (Troubleshooting) – Subsection 5.1: "Analyze and troubleshoot system-related issues" (specifically focusing on Performance and Process Monitoring).
Reference: Linux Man Pages (man uptime, man sar); Official CompTIA Linux+ Study Guide, Chapter on Performance Monitoring.
| Page 4 out of 15 Pages |