Free CompTIA XK0-006 Practice Questions 2026 - Page 2

System Management
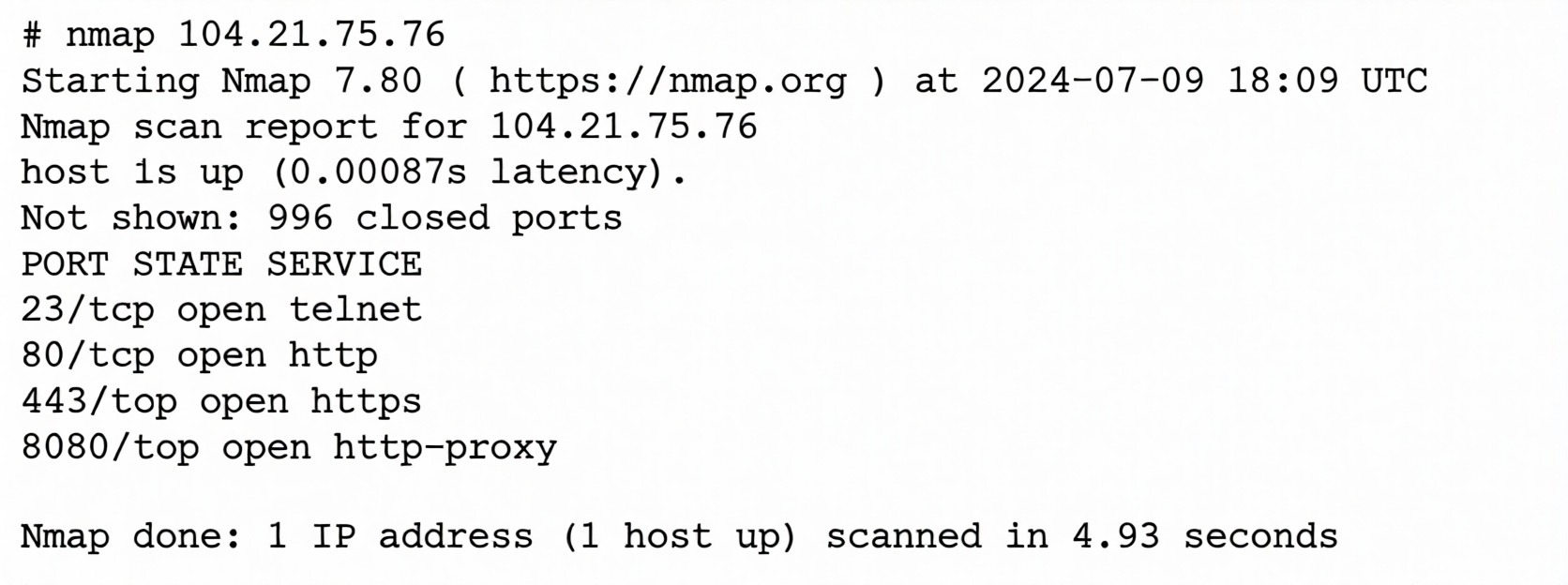
While hardening a system, an administrator runs a port scan with Nmap, which returned the following output:
Which of the following is the best way to address this security issue?
A. Configuring a firewall to block traffic on port 23 on the server
B. Changing the system administrator's password to prevent unauthorized access
C. Closing port 80 on the network switch to block traffic
D. Disabling and removing the Telnet service on the server
Explanation:
The Nmap scan reveals that port 23 (telnet) is open on the server. Telnet is an outdated, insecure protocol that transmits all data, including login credentials, in cleartext (unencrypted). This presents a significant security vulnerability.
Analysis of the Nmap output:
PORT STATE SERVICE
23/tcp open telnet # ⚠️ INSECURE - transmits in cleartext
80/tcp open http # Web server (can be secure with HTTPS)
443/tcp open https # Secure web server (encrypted)
8080/tcp open http-proxy # Alternative web port
Why Telnet is a security risk:
No encryption: All data (including usernames and passwords) sent in plaintext
Can be intercepted: Anyone on the network can sniff credentials
No integrity checking: Data can be modified in transit
Outdated protocol: Modern alternatives provide encryption
Common attack vector: Frequently targeted by attackers
The best remediation:
Disabling and removing the Telnet service addresses the root cause by eliminating the vulnerable service entirely. This is a complete and permanent solution.
Why other options are incorrect:
❌ Configuring a firewall to block traffic on port 23 on the server
This is a workaround, not a fix
The Telnet service would still be running and could be:
* Re-enabled by accident
* Accessed if firewall rules change or fail
* Accessed from localhost (bypassing firewall)
Leaves unnecessary software installed (increases attack surface)
Better to remove the service entirely (defense in depth)
❌ Changing the system administrator's password to prevent unauthorized access
Does NOT address the vulnerability
Passwords sent via Telnet are still exposed in cleartext
Attackers can sniff the new password just as easily
Focuses on credential strength, not the insecure protocol
❌ Closing port 80 on the network switch to block traffic
Wrong port: Port 80 (HTTP) is not the security issue
Port 80 is legitimate web traffic
Blocking at the switch is network-level, not system hardening
Doesn't address the Telnet vulnerability at all
Would break legitimate web services
Secure Alternatives to Telnet:
Protocol Port Encryption Use Case
SSH 22 ✅ Yes Secure remote shell access
SCP/SFTP 22 ✅ Yes Secure file transfer
HTTPS 443 ✅ Yes Secure web access
To properly secure the system:
# 1. Stop the Telnet service immediately
sudo systemctl stop telnet.socket
sudo systemctl stop telnet.service
# 2. Disable Telnet from starting on boot
sudo systemctl disable telnet.socket
sudo systemctl disable telnet.service
# 3. Remove Telnet packages entirely
# On RHEL/CentOS/Fedora:
sudo dnf remove telnet-server telnet
# On Debian/Ubuntu:
sudo apt remove telnetd telnet
# 4. Ensure SSH is installed and properly configured
sudo systemctl enable --now sshd
# 5. Verify the port is closed
nmap localhost
# or
ss -lnt | grep :23
Security Best Practices:
Principle of Least Functionality: Remove or disable unnecessary services
Defense in Depth: Multiple layers of security (remove service + firewall)
Encrypt Everything: Use encrypted protocols (SSH instead of Telnet)
Regular Audits: Periodic port scans to detect open ports
Service Management: Only run services that are required
Reference:
Telnet (RFC 854) - No encryption, credentials in plaintext
NIST Guidelines: Remove or disable unnecessary network services
CIS Benchmarks: Recommend disabling Telnet and using SSH instead
PCI DSS Requirement 2.2.2: Disable all insecure services and protocols
| Page 2 out of 15 Pages |