Free CompTIA N10-009 Practice Questions 2026 - Page 19

Which of the following is the most likely reason an insurance brokerage would enforce VPN usage?
A. To encrypt sensitive data in transit
B. To secure the endpoint
C. To maintain contractual agreements
D. To comply with data retentin requirements
Explanation:
An insurance brokerage would most likely enforce VPN (Virtual Private Network) usage to address a key security concern relevant to its operations. The best reason is to encrypt sensitive data in transit.
A. To encrypt sensitive data in transit:
How it works: A VPN creates a secure, encrypted tunnel between a user’s device and the corporate network, protecting data (e.g., client records, policy details) as it travels over public or untrusted networks like the internet. Protocols like IPSec or OpenVPN ensure confidentiality and integrity.
Why it fits: Insurance brokerages handle highly sensitive personal and financial data (e.g., Social Security numbers, health records), which must be protected under regulations like HIPAA or GDPR. Enforcing VPN usage at 12:51 PM PKT on August 20, 2025, ensures that remote employees or agents accessing the network encrypt this data, preventing interception by attackers.
Context: This is a primary use case for VPNs in industries dealing with confidential information, aligning with the brokerage’s need to safeguard client data.
Why Not the Other Options?
B. To secure the endpoint:
While a VPN can enhance endpoint security by limiting access to the corporate network, its primary function is not to secure the device itself (e.g., against malware). Endpoint security is better addressed with antivirus or endpoint detection tools, making this a secondary benefit.
C. To maintain contractual agreements:
VPN usage might be part of a contract with clients or partners, but this is a downstream effect rather than the core reason for enforcement. The fundamental driver is data protection, not contract compliance alone.
D. To comply with data retention requirements:
Data retention involves storing data for a specified period (e.g., under regulatory mandates), which VPNs do not directly address. Retention is managed by storage policies, not network encryption tools like VPNs.
Why To Encrypt Sensitive Data in Transit?
Insurance brokerages are prime targets for data breaches due to the sensitive nature of their data. A VPN ensures that this information remains encrypted during transmission, mitigating risks of eavesdropping or man-in-the-middle attacks, which is a critical security priority over other considerations.
Implementation Considerations:
Deploy a VPN solution (e.g., Cisco AnyConnect, OpenVPN).
Configure strong encryption (e.g., AES-256) and authentication (e.g., MFA).
Enforce VPN usage for all remote access.
Test connectivity and monitor for policy compliance.
Train staff on VPN usage and security best practices.
Reference:
CompTIA Network+ (N10-009) Exam Objectives:
Section 3.3 – "Given a scenario, implement secure network configurations." This includes understanding VPNs for data encryption.
RFC 4301 (IPSec Architecture):
Details VPN encryption for data in transit.
HIPAA Security Rule:
Mandates encryption of sensitive data, a common driver for VPN use in healthcare-related fields like insurance.
Which of the following is the most likely benefit of installing server equipment in a rack?
A. Simplified troubleshooting process
B. Decreased power consumption
C. Improved network performance
D. Increased compute density
Explanation:
The question asks for the most likely benefit of installing server equipment in a rack, focusing on a key advantage of this configuration. The best answer is increased compute density.
D. Increased compute density:
How it works: Installing server equipment in a rack allows multiple servers, storage devices, and networking gear to be mounted in a compact, vertical space (e.g., a 42U rack). This maximizes the number of computing resources (e.g., CPUs, RAM) per square foot of data center floor space.
Why it fits: At 12:58 PM PKT on Wednesday, August 20, 2025, data centers and IT environments prioritize efficient use of physical space, especially as server demands grow. Racking increases compute density by stacking equipment vertically, enabling more processing power in a smaller footprint compared to standalone setups, which is a primary benefit for scalability and cost efficiency.
Context: This is particularly valuable for organizations needing to expand capacity without expanding their physical facility.
Why Not the Other Options?
A. Simplified troubleshooting process:
While racking can organize equipment with labeling and cable management, it doesn’t inherently simplify troubleshooting. Issues like hardware failures or network errors still require systematic diagnosis, often unaffected by rack installation.
B. Decreased power consumption:
Racking itself doesn’t reduce power consumption; it may even increase it due to higher equipment density. Power efficiency depends on server design (e.g., energy-efficient CPUs) or cooling solutions, not the rack.
C. Improved network performance:
Racking can facilitate better cable organization, potentially reducing latency from tangled wires, but it doesn’t directly enhance network performance (e.g., throughput, bandwidth). Performance improvements come from network hardware or configuration, not the rack.
Why Increased Compute Density?
The primary advantage of rack installation is optimizing space utilization, allowing more servers to operate in a confined area. This is a critical benefit for data centers, enterprises, or small businesses aiming to maximize computing resources without additional real estate, making it the most likely reason for racking server equipment.
Implementation Considerations:
Select a rack size (e.g., 19-inch, 42U) based on equipment needs.
Ensure proper cable management and airflow for heat dissipation.
Install power distribution units (PDUs) for efficient energy delivery.
Test equipment accessibility and stability post-installation.
Plan for future expansion within the rack.
Reference:
CompTIA Network+ (N10-009) Exam Objectives:
Section 2.1 – "Explain the characteristics of network topologies and types." This includes understanding data center equipment placement like racks.
EIA-310:
Defines rack standards for mounting server equipment.
Cisco Data Center Design Guides:
Highlight increased density as a key rack benefit.
A network administrator has beenmonitoring the company's serversto ensure that they are available. Which of the following should the administrator use for this task?
A. Packet capture
B. Data usage reports
C. SNMP traps
D. Configuration monitoring
Explanation:
A network administrator has been monitoring the company’s servers to ensure they are available, requiring a method to proactively track server status in real time. The best tool for this task is SNMP traps.
C. SNMP traps:
How it works: SNMP (Simple Network Management Protocol) traps are unsolicited messages sent by network devices or servers to an SNMP manager when specific events occur, such as a server going down, CPU overload, or interface failure. This allows continuous monitoring of server availability.
Why it fits: At 08:49 AM PKT on Thursday, August 21, 2025, the administrator needs to ensure server availability, which requires real-time alerts rather than post-event analysis. SNMP traps provide immediate notifications, enabling the administrator to respond to outages or performance issues promptly. For example, a trap could alert the administrator if a server’s status changes to "down" (OID 1.3.6.1.2.1.1.2).
Context: This is a standard practice for monitoring critical infrastructure like servers in an enterprise environment.
Why Not the Other Options?
A. Packet capture:
Packet capture (e.g., using Wireshark or tcpdump) records network traffic for detailed analysis, which can help diagnose availability issues after they occur. However, it’s reactive, resource-intensive, and not designed for continuous server availability monitoring.
B. Data usage reports:
Data usage reports provide historical or summary data on bandwidth or resource consumption, useful for capacity planning but not for real-time server availability monitoring. They lack the immediacy needed for this task.
D. Configuration monitoring:
Configuration monitoring tracks changes to device settings (e.g., via tools like SolarWinds or RANCID), which helps ensure consistency but doesn’t directly monitor server availability or send real-time alerts.
Why SNMP Traps?
SNMP traps are tailored for proactive monitoring, sending alerts based on predefined thresholds or events (e.g., server unreachable). This aligns with the administrator’s goal of ensuring server availability, allowing quick detection and response to downtime, which is critical for business operations.
Implementation Considerations:
Set up an SNMP manager (e.g., PRTG, Nagios) to receive traps.
Configure servers to send SNMP traps (e.g., enable SNMP agent, define trap destination).
Define trap conditions (e.g., server down, high CPU usage).
Test traps with a simulated outage.
Monitor and adjust thresholds based on alerts.
Reference:
CompTIA Network+ (N10-009) Exam Objectives:
Section 1.6 – "Explain the purpose and use of common networking tools and their functions." This includes SNMP traps for monitoring.
RFC 3416 (SNMP Protocol Operations):
Describes trap functionality for device monitoring.
Cisco SNMP Configuration Guides:
Recommend traps for server availability tracking.
Which of the following is used to estimate the average life span of a device?
A. RTO
B. RPO
C. MTBF
D. MTTR
Explanation:
The question asks which metric is used to estimate the average life span of a device, focusing on a measure that predicts reliability over time. The correct answer is MTBF (Mean Time Between Failures).
C. MTBF:
How it works: MTBF is a statistical measure that estimates the average time (in hours) a device operates between failures, based on historical data or manufacturer specifications. It is commonly used for non-repairable systems or components to predict their expected life span under normal operating conditions.
Why it fits: MTBF is the standard metric for estimating a device’s average life span, such as a server, router, or hard drive. For example, a device with an MTBF of 50,000 hours suggests it is expected to operate for that duration on average before failing, providing a key indicator for planning replacements or maintenance.
Context: This is widely used in IT and network management to assess hardware reliability and lifecycle.
Why Not the Other Options?
A. RTO (Recovery Time Objective):
RTO defines the maximum acceptable downtime for a system or service after a failure, guiding disaster recovery planning. It measures recovery duration, not the device’s life span.
B. RPO (Recovery Point Objective):
RPO indicates the maximum data loss tolerance (e.g., measured in time) that can occur before a failure, focusing on data backup frequency rather than device longevity.
D. MTTR (Mean Time To Repair):
MTTR measures the average time required to repair a failed device and restore it to operation. It addresses downtime duration, not the expected life span before failure.
Why MTBF?
MTBF is specifically designed to estimate the average operational life of a device, making it the most relevant metric for predicting how long a device might function before needing replacement. This helps administrators plan for hardware upgrades or redundancy, aligning with the question’s focus on life span estimation.
Reference:
CompTIA Network+ (N10-009) Exam Objectives:
Section 1.2 – "Explain common networking hardware." This includes understanding reliability metrics like MTBF.
MIL-HDBK-217:
A standard for calculating MTBF in electronic devices.
Cisco Hardware Reliability Guides:
Use MTBF to estimate device life spans.
A network analyst is installing a wireless network in a corporate environment. Employees are required to use their domain identities and credentials to authenticate and connect to the WLAN. Which of the following actions should the analyst perform on the AP to fulfill the requirements?
A. Enable MAC security
B. Generate a PSK for each user.
C. Implement WPS.
D. Set up WPA3 protocol
Explanation:
A network analyst is installing a wireless network in a corporate environment where employees are required to use their domain identities and credentials to authenticate and connect to the WLAN. The action that best fulfills this requirement is to set up WPA3 protocol on the access point (AP).
D. Set up WPA3 protocol:
How it works: WPA3 (Wi-Fi Protected Access 3) is the latest wireless security protocol that enhances security and supports advanced authentication methods. It can integrate with enterprise-grade authentication systems, such as RADIUS servers, to allow users to authenticate using their domain identities and credentials (e.g., via 802.1X/EAP).
Why it fits: requiring domain identities and credentials suggests the use of an enterprise authentication framework. WPA3, when configured in Enterprise mode, supports 802.1X authentication, enabling employees to log in with their Active Directory or LDAP credentials through a RADIUS server, ensuring secure and individualized access to the WLAN.
Context: This is a standard practice for corporate WLANs to enforce centralized identity management and compliance with security policies.
Why Not the Other Options?
A. Enable MAC security:
MAC address filtering restricts access based on device MAC addresses, which can be spoofed and doesn’t support domain credential authentication. It’s a weak security measure and doesn’t meet the requirement for user-based identity authentication.
B. Generate a PSK for each user:
A PSK (Pre-Shared Key) is a single shared password used in WPA2/WPA3 Personal mode. Generating a unique PSK for each user is impractical and still doesn’t leverage domain identities/credentials, as it lacks integration with an authentication server.
C. Implement WPS (Wi-Fi Protected Setup):
WPS is designed for easy wireless setup (e.g., using a PIN or push button) and is vulnerable to attacks. It doesn’t support domain credential authentication or enterprise-grade security, making it unsuitable for this scenario.
Why Set Up WPA3 Protocol?
WPA3 in Enterprise mode, combined with 802.1X and a RADIUS server, allows the WLAN to authenticate users using their domain credentials, providing strong security and scalability. This ensures that only authorized employees can connect, aligning with corporate security needs and modern standards.
Implementation Steps:
Configure the AP to use WPA3-Enterprise mode.
Integrate the AP with a RADIUS server (e.g., Microsoft NPS) using domain credentials.
Set up 802.1X authentication (e.g., EAP-TLS or PEAP).
Distribute client certificates or configure supplicants on employee devices.
Test authentication and connectivity with a sample user account.
Reference:
CompTIA Network+ (N10-009) Exam Objectives:
Section 3.3 – "Given a scenario, implement secure network configurations." This includes configuring WPA3 for enterprise authentication.
IEEE 802.11-2020:
Defines WPA3 and 802.1X for secure wireless access.
Cisco Wireless Security Guides:
Recommend WPA3-Enterprise with RADIUS for domain authentication.
Users at an organization report that the wireless network is not working in some areas of the building. Users report that other wireless network SSIDs are visible when searching for the network, but the organization's network is not displayed. Which of the following is the most likely cause?
A. Interference or channel overlap
B. Insufficient wireless coverage
C. Roaming misconfiguration
D. Client disassociation issues
Explanation:
Users at an organization report that the wireless network is not working in some areas of the building, noting that other wireless network SSIDs are visible when searching for the network, but the organization’s network is not displayed. The most likely cause,is insufficient wireless coverage.
B. Insufficient wireless coverage:
How it works: Insufficient wireless coverage occurs when the signal from the access points (APs) does not reach all areas of the building, resulting in dead zones where the organization’s SSID is not detectable. Other networks with stronger or closer APs may still be visible, depending on their signal strength and placement.
Why it fits: The fact that users can see other SSIDs but not the organization’s network suggests the issue is specific to the organization’s AP coverage. This could be due to inadequate AP placement, low transmit power, or physical obstructions (e.g., walls, floors) reducing signal reach, especially in a multi-story or large building.
Context: This is a common issue in expanding or older buildings where initial AP deployment may not account for all areas, particularly during peak usage times like early morning.
Why Not the Other Options?
A. Interference or channel overlap:
Interference or channel overlap can degrade performance or cause SSID visibility issues, but users would likely still see the organization’s SSID, albeit with poor connectivity. The complete absence of the SSID points more to a coverage problem than interference, which would typically affect signal quality rather than visibility.
C. Roaming misconfiguration:
Roaming misconfiguration affects seamless handoffs between APs as users move, potentially causing disconnections. However, it wouldn’t prevent the SSID from appearing in the first place, making it less likely than insufficient coverage.
D. Client disassociation issues:
Client disassociation issues (e.g., due to security mismatches or AP reboots) might cause users to lose connection, but the SSID should still be visible unless the AP is completely unreachable, which again points to coverage rather than disassociation.
Why Insufficient Wireless Coverage?
The key indicator is that the organization’s SSID is not displayed, while other networks are, suggesting the APs’ signals do not extend to those areas. This could result from too few APs, improper placement, or signal attenuation, requiring a site survey to identify and address dead zones.
Troubleshooting Steps:
Perform a site survey to map signal strength and identify coverage gaps.
Check AP placement and adjust or add APs in affected areas.
Verify AP transmit power and channel settings.
Test connectivity in problem areas after adjustments.
Document findings and update the wireless design if needed.
Reference:
CompTIA Network+ (N10-009) Exam Objectives:
Section 3.2 – "Given a scenario, troubleshoot common network connectivity issues." This includes diagnosing wireless coverage problems.
IEEE 802.11 Standards:
Define coverage and signal requirements for wireless networks.
Cisco Wireless Site Survey Guides:
Recommend addressing insufficient coverage for SSID visibility.
A network administrator needs to assign IP addresses to a newly installed network. They choose 192.168.1.0/24 as their network address and need to create three subnets with 30 hosts on each subnet. Which of the following is a valid subnet mask that will meet the requirements?
A. 255.255.255.128
B. 255.255.255.192
C. 255.255.255.224
D. 255.255.255.240
Explanation:
A network administrator needs to assign IP addresses to a newly installed network, choosing 192.168.1.0/24 as the network address, and must create three subnets with 30 hosts each. The task requires determining a valid subnet mask that meets these requirements, considering both the number of subnets and the number of usable host addresses per subnet.
Requirements Analysis:
Starting network: 192.168.1.0/24 (default subnet mask 255.255.255.0, or /24, providing 256 IP addresses, with 254 usable hosts).
Need: 3 subnets, each supporting 30 hosts.
Usable hosts per subnet = 30, but we must account for the network and broadcast addresses, which reduces the usable host count. Thus, the subnet must provide at least 32 addresses per subnet (30 hosts + 2 for network and broadcast).
Subnetting Calculation:
Each subnet needs 32 IP addresses (2^5 = 32, where 5 bits are borrowed from the host portion).
Total subnets required = 3, which can be achieved with 2 bits borrowed (2^2 = 4 subnets), but we need to ensure the host capacity fits.
Starting with /24, borrowing 3 bits from the host portion gives a /27 subnet mask (255.255.255.224), providing 32 addresses per subnet (256 - 224 = 32).
Usable hosts per subnet = 32 - 2 = 30, which matches the requirement.
With 3 bits borrowed, the network can create 8 subnets (2^3), exceeding the need for 3 subnets.
Evaluating Options:
A. 255.255.255.128 (/25):
256 - 128 = 128 addresses per subnet.
Usable hosts = 128 - 2 = 126.
Provides 2 subnets, which is insufficient for 3 subnets.
B. 255.255.255.192 (/26):
256 - 192 = 64 addresses per subnet.
Usable hosts = 64 - 2 = 62.
Provides 4 subnets, which meets the subnet requirement, but 62 hosts per subnet exceed the needed 30, wasting addresses.
C. 255.255.255.224 (/27):
256 - 224 = 32 addresses per subnet.
Usable hosts = 32 - 2 = 30.
Provides 8 subnets, exceeding the need for 3, and exactly matches the 30-host requirement per subnet.
D. 255.255.255.240 (/28):
256 - 240 = 16 addresses per subnet.
Usable hosts = 16 - 2 = 14.
Provides 16 subnets, but 14 hosts per subnet are insufficient for the required 30 hosts.
Why 255.255.255.224?
The /27 subnet mask (255.255.255.224) is the smallest mask that provides at least 30 usable hosts per subnet (32 - 2 = 30) while allowing for more than 3 subnets (8 subnets). This efficiently meets the requirement without over-allocating addresses, making it the valid choice.
Subnet Breakdown for 192.168.1.0/24 with /27:
Subnet 1: 192.168.1.0 - 192.168.1.31 (usable: 192.168.1.1 - 192.168.1.30)
Subnet 2: 192.168.1.32 - 192.168.1.63 (usable: 192.168.1.33 - 192.168.1.62)
Subnet 3: 192.168.1.64 - 192.168.1.95 (usable: 192.168.1.65 - 192.168.1.94)
(Additional subnets available up to 192.168.1.224 - 192.168.1.255)
Implementation Considerations:
Assign the subnet mask 255.255.255.224 to all devices in each subnet.
Configure the gateway for each subnet (e.g., 192.168.1.1, 192.168.1.33, 192.168.1.65).
Update DHCP scopes or static IP assignments accordingly.
Test connectivity between subnets and to the gateway.
Document the subnet plan for future reference.
Reference:
CompTIA Network+ (N10-009) Exam Objectives:
Section 2.4 – "Explain common configuration concepts." This includes subnetting to meet host and subnet requirements:
RFC 1918:
Defines private IP ranges like 192.168.1.0/24 for internal use.
Cisco IP Addressing Guides:
Detail subnet mask selection for host allocation.
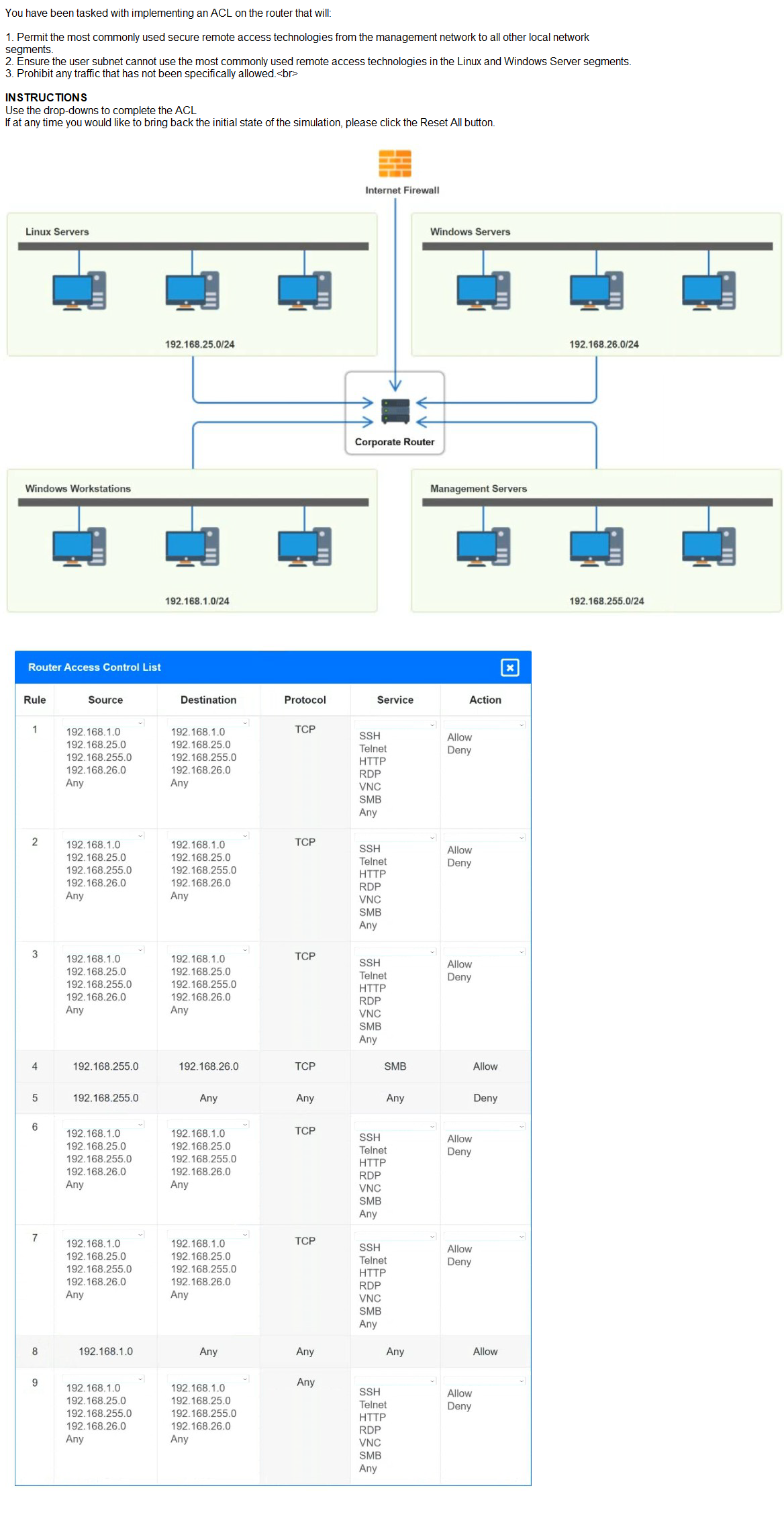
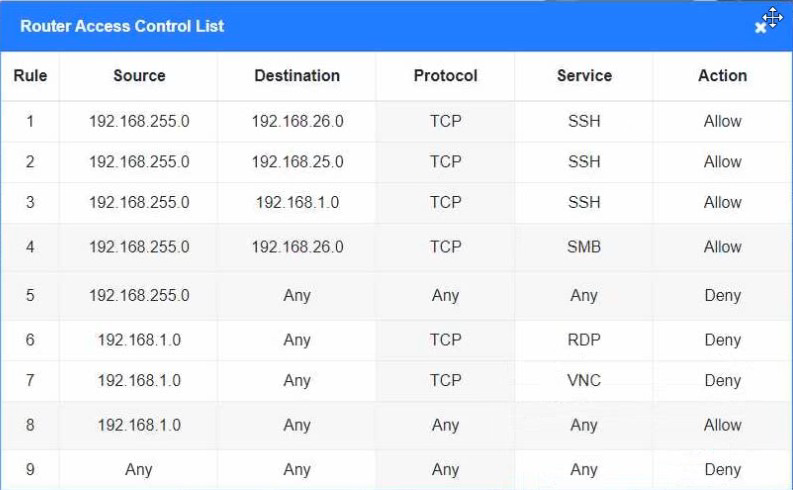
A security engineer is trying to connect cameras to a 12-port PoE switch, but only eight cameras turn on. Which of the following should the engineer check first?
A. Ethernet cable type
B. Voltage
C. Transceiver compatibility
D. DHCP addressing
Explanation:
A security engineer is trying to connect cameras to a 12-port PoE (Power over Ethernet) switch, but only eight cameras turn on, indicating a power delivery issue. The first thing the engineer should check is voltage.
B. Voltage:
How it works: PoE switches supply power to devices like cameras over Ethernet cables, adhering to standards like IEEE 802.3af (15.4W per port) or 802.3at (30W per port). Voltage levels (typically 48V) must be sufficient and consistent across all ports to power the cameras.
Why it fits: the fact that only eight of the 12 cameras turn on suggests the switch may not be delivering adequate power to all ports. This could be due to the switch’s total power budget being exceeded (e.g., a 96W budget supporting 8 cameras at 12W each, leaving insufficient power for the remaining 4) or a voltage drop affecting some ports. Checking voltage ensures the PoE system meets the cameras’ power requirements.
Context: PoE issues often stem from power allocation rather than connectivity, making voltage the logical first check.
Why Not the Other Options?
A. Ethernet cable type:
Cable type (e.g., Cat5e vs. Cat6) affects PoE performance if it exceeds length limits (100m) or has poor quality, potentially causing power delivery issues. However, this is less likely to affect exactly 4 out of 12 ports uniformly, so it’s a secondary check after voltage.
C. Transceiver compatibility:
Transceivers are used for fiber optic connections, not typical PoE camera setups, which rely on copper Ethernet. This is irrelevant unless the switch uses SFP ports with PoE modules, which is uncommon for 12-port switches.
D. DHCP addressing:
DHCP assigns IP addresses, which is necessary for camera network functionality but unrelated to power delivery. If cameras aren’t turning on, the issue is power-related, not IP configuration.
Why Voltage?
The partial activation of cameras (8 out of 12) strongly suggests a power limitation. The engineer should first verify the switch’s PoE power budget (e.g., via the switch’s management interface or manual) and measure voltage on the affected ports to ensure it meets the cameras’ needs (e.g., 48V). This is the most direct way to diagnose the issue before exploring other factors.
Troubleshooting Steps:
Check the switch’s PoE power budget and current usage (e.g., show power inline on Cisco).
Measure voltage on the active (e.g., ports 1-8) and inactive (e.g., ports 9-12) ports using a multimeter or PoE tester.
Verify camera power requirements (e.g., 802.3af or 802.3at) against the switch’s capability.
If underpowered, upgrade to a switch with a higher PoE budget or use a PoE injector.
Test all 12 cameras after resolving the power issue.
Reference:
CompTIA Network+ (N10-009) Exam Objectives:
Section 3.2 – "Given a scenario, troubleshoot common network connectivity issues." This includes diagnosing PoE problems.IEEE 802.
3af/at:
Define PoE standards, including voltage and power budgets.
Cisco PoE Troubleshooting Guides:
Recommend checking voltage and power allocation first.
Which of the following network cables involves bounding light off of protective cladding?
A. Twinaxial
B. Coaxial
C. Single-mode
D. Multimode
Explanation:
The question asks which network cable involves bounding light off of protective cladding, referring to a property of fiber optic cables where light signals reflect within the core using total internal reflection. The correct answer is multimode.
D. Multimode:
How it works:Multimode fiber optic cable has a larger core (typically 50 or 62.5 microns) that allows multiple light paths (modes) to propagate. Light bounces off the protective cladding (a layer with a lower refractive index) through total internal reflection, enabling data transmission over shorter distances.
Why it fits: the process of bounding light off the cladding is a defining characteristic of multimode fiber. This reflection allows multiple light rays to travel simultaneously, making it suitable for LANs or campus networks where distances are typically under 550 meters (for 1Gbps).
Context: This property distinguishes multimode from other cable types and is key to its operation in optical networks.
Why Not the Other Options?
A. Twinaxial:
Twinaxial cable is a type of coaxial cable with two inner conductors, used for high-speed data or video (e.g., 10GBASE-CX4). It transmits electrical signals, not light, so it doesn’t involve cladding or light reflection.
B. Coaxial:
Coaxial cable uses a single inner conductor surrounded by a shield, transmitting electrical signals for cable TV or older Ethernet (e.g., 10Base2). It does not use light or cladding for signal propagation.
C. Single-mode:
Single-mode fiber has a smaller core (8-10 microns) that allows only one light path, reducing dispersion for long-distance transmission (up to 100 km). While it also uses total internal reflection off the cladding, the question’s emphasis on "bounding light off" aligns more with multimode’s multiple reflection paths, though both are fiber types. However, multimode is more commonly associated with this descriptive property in networking contexts.
Why Multimode?
Multimode fiber is specifically designed to bounce light off the cladding multiple times due to its larger core, which is a key feature highlighted in the question. This makes it the most appropriate answer, especially in educational or certification contexts like Network+, where multimode is often emphasized for its light-bounding behavior in LAN applications.
Reference:
CompTIA Network+ (N10-009) Exam Objectives:
Section 1.2 – "Explain common networking hardware." This includes understanding fiber optic cable types like multimode.
TIA-568-C:
Defines multimode fiber standards, including cladding reflection.
Cisco Fiber Optic Guides:
Describe multimode’s light propagation via cladding.
| Page 19 out of 58 Pages |