Free CompTIA CV0-004 Practice Questions 2026 - Page 6

An organization is hosting a seminar with eight individuals who need to connect to their
own dedicated VM. The technician used the following VM configurations:
IP address: DHCP
NIC: 1Gbps
Network: 10.1.10.0/29
Several users are unable to access their VMs. Which of the following best describes the
reason?
A. Not enough addresses are available
B. The routes are misconfigured
C. Too much traffic is on the network.
D. DHCP is not working correctly on the VM.
Explanation:
The issue here is a simple subnetting calculation error.
The Math
The technician configured the network as 10.1.10.0/29.
A /29 subnet has a total of 8 IP addresses.
However, in any subnet, 2 addresses are reserved: one for the Network ID (10.1.10.0) and one for the Broadcast Address (10.1.10.7).
This leaves only 6 usable IP addresses.
The Problem
There are 8 individuals who each need their own dedicated VM. Since there are only 6 usable IPs available in a /29 subnet, at least two users will be unable to obtain an IP address from DHCP and will fail to connect.
Why Other Options are Incorrect
B. The routes are misconfigured
While routing issues can cause connectivity problems, the primary bottleneck here is the physical lack of available IP addresses for the number of requested hosts.
C. Too much traffic on the network
A 1Gbps NIC is more than enough bandwidth for standard VM access for 8 people. "Traffic" usually results in slowness (latency), not a total inability to "access" or assign an IP to the VM.
D. DHCP is not working correctly on the VM
DHCP is a service provided by the network, not the VM itself. The VM's DHCP client is likely working fine, but it is receiving a "No addresses available" response (or no response at all) from the pool.
Exam Context
This falls under Domain 2.0: Cloud Networking. For the CV0-004, you must be comfortable with CIDR notation and calculating usable hosts. To support 8 individuals, the technician should have used at least a /28 subnet (14 usable addresses).
Which of the following describes what CRUD is typically used for?
A. Relational databases
B. Time series databases
C. Graph databases
D. NoSQL databases
Explanation:
CRUD stands for:
- Create
- Read
- Update
- Delete
These are the four basic operations used to manage data in a database.
CRUD is most commonly associated with Relational databases, where:
- Data is stored in structured tables
- Operations map directly to SQL commands:
Create → INSERT
Read → SELECT
Update → UPDATE
Delete → DELETE
In CompTIA exams, CRUD is strongly tied to traditional SQL-based systems.
Why the other options are wrong
B. Time series databases
Designed for timestamped data (e.g., monitoring metrics)
While CRUD may exist, it's not what they are typically known for
C. Graph databases
Focus on relationships (nodes and edges)
Use query languages like Cypher, not classic CRUD terminology
D. NoSQL databases
May support CRUD-like operations
But are typically described using key-value, document, or column-based models, not CRUD as the defining concept
Exam Tip
If you see:
- CRUD
- SQL commands (INSERT, SELECT, etc.)
- Structured tables
Think immediately: Relational databases
A cloud engineer is running a latency-sensitive workload that must be resilient and highly available across multiple regions. Which of the following concepts best addresses these requirements?
A. Cloning
B. Clustering
C. Hardware passthrough
D. Stand-alone container
Explanation:
The cloud engineer is running a latency-sensitive workload that must be resilient and highly available across multiple regions. The key requirements are:
- Low latency (implies proximity to users or fast failover)
- Resilience (ability to recover from failures)
- High availability across multiple regions (no single point of failure, geographic distribution)
B. Clustering
Clustering refers to grouping multiple servers (or nodes) together to work as a single system. When deployed across multiple regions, clustering provides:
✅ High availability — if one node or region fails, traffic is routed to healthy nodes in other regions
✅ Resilience — workloads are distributed across nodes, reducing the impact of individual failures
✅ Latency optimization — with global load balancing, traffic can be directed to the closest healthy node, minimizing latency for end users
✅ Active-active configurations — multiple nodes handle traffic simultaneously, allowing immediate failover without downtime
Examples include database clusters (e.g., multi-region Aurora Global Database), Kubernetes clusters spanning multiple regions, or application clusters behind a global load balancer.
Why the other options are incorrect
A. Cloning
Cloning creates an exact copy of a server or instance. While cloning can be used to create redundant instances, it does not by itself provide automated failover, health monitoring, or traffic distribution. Cloning is a method for creating copies, not a complete high-availability architecture across regions.
C. Hardware passthrough
Hardware passthrough allows a VM or container to directly access physical hardware (e.g., GPU, NIC). This is used for performance-intensive workloads but reduces portability and resilience. It ties the workload to specific physical hardware, making high availability across regions difficult or impossible to achieve.
D. Stand-alone container
A stand-alone container is a single instance with no built-in redundancy. It does not provide resilience or high availability. If the container or its host fails, the workload becomes unavailable until manually recovered.
Reference
CompTIA Cloud+ CV0-004 Exam Objectives:
Domain 1.0: Cloud Architecture and Design
1.4: Given a scenario, design a high availability and disaster recovery solution. Includes clustering, multi-region deployments, and load balancing to achieve resilience and availability.
Domain 3.0: Operations and Support
3.3: Given a scenario, implement high availability and disaster recovery in a cloud environment. Covers clustering across availability zones and regions.
Industry Best Practices
Multi-region clustering combined with global load balancing is the standard architecture for latency-sensitive, highly available workloads in the cloud. Services like AWS Global Accelerator, Azure Traffic Manager, and Google Cloud Load Balancing route traffic to the nearest healthy cluster node, ensuring both low latency and resilience against regional failures.
A cloud engineer hardened the WAF for a company that operates exclusively in North America. The engineer did not make changes to any ports, and all protected applications have continued to function as expected. Which of the following configuration changes did the engineer most likely apply?
A. The engineer implemented MFA to access the WAF configurations
B. The engineer blocked all traffic originating outside the region.
C. The engineer installed the latest security patches on the WAF.
D. The engineer completed an upgrade from TLS version 1.1 to version 1.3.
Explanation:
In cloud security, "hardening" involves reducing the attack surface of a resource. Since the company operates exclusively in North America, any traffic originating from other parts of the globe (Europe, Asia, etc.) is likely unnecessary and represents a potential security risk (such as botnet probes or unauthorized access attempts).
The engineer likely implemented Geoblocking (or Geographic Filtering) on the Web Application Firewall (WAF). This configuration change:
- Hardens the WAF: It immediately eliminates a massive percentage of global automated attacks.
- Does not change ports: Geoblocking filters by IP address origin, not by TCP/UDP ports (e.g., 80 or 443 remain open for legitimate users).
- Maintains expected functionality: Since legitimate customers are only in North America, they are unaffected by the block.
Incorrect Answers
A. The engineer implemented MFA to access the WAF configurations
While this is a great security practice for administrative access, it hardens the management plane, not the WAF's protection of the applications themselves. It doesn't change how the WAF handles incoming traffic.
C. The engineer installed the latest security patches on the WAF
Most modern Cloud WAFs (like AWS WAF or Azure WAF) are managed services where the cloud provider handles underlying patching. Furthermore, patching is standard maintenance and wouldn't be described as a "configuration change" that specifically aligns with the company's "exclusive North American" footprint.
D. The engineer completed an upgrade from TLS version 1.1 to version 1.3
While this is a form of hardening (deprecated protocol removal), it could potentially cause "protected applications" to fail for users with older browsers. The prompt emphasizes that everything "continued to function as expected," making Geoblocking a more likely and targeted fit for the business context provided.
Reference
CompTIA Cloud+ (CV0-004) Objective:
Domain 4.0: Security and Compliance
Section 4.1: Given a scenario, configure network security (e.g., WAF, Geoblocking, IP filtering).
Section 4.2: Given a scenario, configure security technologies (e.g., hardening).
An administrator needs to adhere to the following requirements when moving a customer's
data to the cloud:
• The new service must be geographically dispersed.
• The customer should have local access to data
• Legacy applications should be accessible.
Which of the following cloud deployment models is most suitable?
A. On-premises
B. Private
C. Hybrid
D. Public
Explanation:
The Hybrid cloud deployment model is the most suitable because it directly satisfies all three requirements:
- Geographically dispersed: The public cloud portion of a hybrid environment can span multiple regions and availability zones worldwide, providing true geographic dispersion and redundancy.
- Local access to data: Sensitive or latency-sensitive data can remain on-premises (or in a private cloud close to the customer), ensuring low-latency local access without sending everything over the internet.
- Legacy applications accessible: Older/legacy applications that are difficult to refactor or migrate can continue running on-premises (or in the private portion), while newer workloads or scalable services run in the public cloud. Connectivity between on-premises and cloud (via VPN, Direct Connect, etc.) keeps everything accessible as a unified environment.
Hybrid cloud is specifically designed for organizations that need the benefits of public cloud (scalability, cost-efficiency) while retaining control over certain data and legacy systems on-premises.
Why the other options are incorrect
A. On-premises
Keeps everything in the customer’s own data center. It provides local access and supports legacy apps, but it is not geographically dispersed across cloud regions and lacks the scalability/cost benefits of cloud.
B. Private
A private cloud (whether on-premises or hosted) offers better control and security, and can support legacy apps. However, it is usually limited to a single organization’s infrastructure and is not inherently “geographically dispersed” like public cloud regions. It also doesn’t fully leverage public cloud advantages.
D. Public
A public cloud (AWS, Azure, Google Cloud, etc.) is highly geographically dispersed and scalable, but it would require moving all data and applications to the cloud. This often breaks legacy apps that aren’t cloud-ready and may not provide true “local” low-latency access for all data if the customer’s users are in a specific geography without optimized edge services.
Key Takeaway for CV0-004 (Cloud+)
This question tests Domain 1.0: Cloud Concepts and Architecture (specifically cloud deployment models: Public, Private, Hybrid, Community, and On-premises).
Hybrid is the go-to model when an organization needs:
- Some workloads in the public cloud (for dispersion and scalability)
- Some resources kept on-premises (for compliance, legacy support, or latency)
It enables cloud bursting, data sovereignty, and gradual migration strategies.
References
CompTIA Cloud+ (CV0-004) Exam Objectives: 1.2 Explain cloud deployment models (Public, Private, Hybrid, Community).
A cloud networking engineer is troubleshooting the corporate office's network configuration.
Employees in the IT and operations departments are unable to resolve IP addresses on all
devices, and the IT department cannot establish a connection to other departments'
subnets. The engineer identifies the following configuration currently in place to support the
office network:
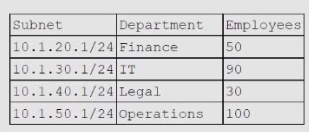
Each employee needs to connect to the network with a maximum of three hosts. Each
subnet must be segregated, but the IT department must have the ability to communicate
with all subnets. Which of the following meet the IP addressing and routing requirements?
(Select two).
A. Modifying the subnet mask to 255 255 254.0 for IT and operations departments
B. Configuring static routing to allow access from each subnet to 10.1.40.1
C. Modifying the BYOD policy to reduce the volume of devices that are allowed to connect to the corporate network
D. Configuring static routing to allow access from 10.1.30.1 to each subnet
E. Combining the subnets and increasing the allocation of IP addresses available to support three hosts for each employee
F. Modifying the subnet mask to 255.255.255.128 for the IT and operations departments
D. Configuring static routing to allow access from 10.1.30.1 to each subnet
Explanation:
Let’s analyze the situation step by step:
Problem 1: Not enough IPs per employee
Each employee needs up to 3 hosts (e.g., workstation, phone, laptop).
- IT has 90 employees × 3 = 270 hosts.
- Operations has 100 employees × 3 = 300 hosts.
Current subnet mask /24 (255.255.255.0) only supports 254 usable IPs.
→ Both IT and Operations departments exceed this limit.
Solution for addressing
- A. Modifying the subnet mask to 255.255.254.0 (/23) → This doubles the available IPs to 510 usable addresses, enough for IT and Operations.
Problem 2: IT cannot connect to other subnets
The requirement states IT must communicate with all departments.
This requires routing between subnets.
- D. Configuring static routing to allow access from 10.1.30.1 (IT subnet) to each subnet → Ensures IT can reach Finance, Legal, and Operations.
Incorrect Options
- B. Configuring static routing to 10.1.40.1 (Legal subnet) → Doesn’t meet the requirement; IT must connect to all subnets, not just Legal.
- C. Modifying BYOD policy → Reduces devices but doesn’t solve subnetting or routing issues.
- E. Combining subnets → Breaks segregation requirement.
- F. Modifying subnet mask to 255.255.255.128 (/25) → Only supports 126 usable IPs, which is insufficient.
Reference
CompTIA Cloud+ (CV0-004) Objectives:
- Domain 2.0 Cloud Infrastructure → Subnetting, IP addressing, routing.
- Domain 3.0 Cloud Deployment → Network segmentation and connectivity requirements.
An engineer made a change to an application and needs to select a deployment strategy
that meets the following requirements:
• Is simple and fast
• Can be performed on two Identical platforms
Which of the following strategies should the engineer use?
A. Blue-green
B. Canary
C. Rolling
D. in-place
Explanation:
✅ A. Blue-green: This deployment strategy uses two identical environments (one active, called "Blue," and one idle, called "Green").
Two identical platforms: This matches the requirement perfectly. You deploy the new version to the "Green" environment while "Blue" handles live traffic.
Simple and fast: Once the "Green" environment is ready, the cutover is as simple and fast as updating a DNS record or a load balancer weight to point to the new platform. If an issue occurs, rolling back is equally fast—you just point traffic back to "Blue."
❌ B. Canary: This involves pushing a change to a small percentage of users first. While effective for testing, it is more complex to set up (requiring detailed traffic routing and monitoring) and is generally slower than a wholesale blue-green switch.
❌ C. Rolling: In a rolling deployment, you update instances one by one or in small batches within a single environment. This is often slower because you must wait for each batch to pass health checks, and it doesn't involve "two identical platforms" in the same way.
❌ D. In-place: This updates the code directly on the live servers. While it might seem "simple," it often involves downtime and is the riskiest method because there is no secondary identical platform to fall back on if the update fails.
Exam Context
This falls under Domain 4.0: Operations and Support (specifically Deployment Technologies and Methods). For CV0-004, remember: Blue-green = Two identical environments.
Which of the following integration systems would best reduce unnecessary network traffic by allowing data to travel bidirectionally and facilitating real-time results for developers who need to display critical information within applications?
A. REST API
B. RPC
C. GraphQL
D. Web sockets
Explanation:
WebSockets provide a persistent, full-duplex (bidirectional) communication channel over a single TCP connection. This is the most efficient method for real-time applications (such as live financial tickers, chat apps, or critical system monitors) because:
Bidirectional Travel: Data can be sent from the client to the server and from the server to the client simultaneously without the overhead of repeated HTTP headers.
Reduced Network Traffic: Unlike traditional polling (where a client repeatedly asks "is there new data?"), WebSockets keep the connection open. The server simply "pushes" data to the client the moment it becomes available, eliminating unnecessary request/response cycles.
Real-time Results: Because there is no need to establish a new connection for every piece of data, latency is significantly lower, allowing developers to display critical information instantly.
Incorrect Answers
A. REST API: Representational State Transfer (REST) is based on a standard Request-Response model. It is unidirectional (the client must initiate the request) and stateless. While common, it is not "real-time" and requires significant overhead for frequent updates.
B. RPC: Remote Procedure Call (RPC) allows a program to cause a procedure to execute in another address space. While efficient for microservices, it typically follows a request-response pattern and is not designed for persistent, bidirectional streaming of real-time application data.
C. GraphQL: GraphQL is a query language for APIs that allows clients to request exactly the data they need. While it reduces "over-fetching" (which saves bandwidth), the standard implementation still uses HTTP request-response. While it supports "Subscriptions" for real-time data, those subscriptions are actually often implemented using WebSockets.
Reference
CompTIA Cloud+ (CV0-004) Objective:
Domain 1.0: Cloud Architecture and Design
Section 1.2: Given a business requirement, analyze the different types of cloud service models and integration patterns (e.g., API types, message queuing).
Domain 2.0: Deployment and Administration
Section 2.1: Given a scenario, deploy cloud solutions (e.g., application integration, microservices).
A cloud engineer is designing a cloud-native, three-tier application. The engineer must
adhere to the following security best practices:
• Minimal services should run on all layers of the stack.
• The solution should be vendor agnostic.
• Virealization could be used over physical hardware.
Which of the following concepts should the engineer use to design the system to best meet
these requirements?
A. Virtual machine
B. Micro services
C. Fan-out
D. Cloud-provided managed services
Explanation:
Microservices is the concept that best meets all the stated security best practices for a cloud-native, three-tier application:
Minimal services should run on all layers of the stack: Microservices architecture breaks the application into small, independent, loosely coupled services. Each service runs in its own process/container with only the minimal code and dependencies needed for its specific function. This reduces the attack surface on every layer (presentation, application, and data tiers) compared to a monolithic design where many functions run together.
The solution should be vendor agnostic: Microservices are typically built using open standards (e.g., REST/gRPC APIs, containers like Docker, orchestration with Kubernetes). They can run on any cloud provider (AWS, Azure, GCP) or even on-premises without being locked into proprietary vendor services.
Virtualization could be used over physical hardware: Microservices are highly portable and designed to run in virtualized environments (VMs) or containers. They work equally well whether deployed on virtual machines or physical servers, giving flexibility in the underlying infrastructure.
This approach aligns perfectly with cloud-native principles, enabling better security through isolation, easier updates/patching of individual services, and independent scaling.
Why the other options are incorrect:
A. Virtual machine: VMs provide virtualization over physical hardware and can be vendor-agnostic to some extent, but they do not inherently enforce “minimal services” per layer. A three-tier app on VMs is often still monolithic or has larger attack surfaces unless further broken down.
C. Fan-out: This is a messaging/pattern technique (e.g., one request fans out to multiple services for parallel processing). It helps with performance/scalability but does not address minimal services on layers, vendor neutrality, or overall system design for security best practices.
D. Cloud-provided managed services: These (e.g., AWS RDS, Azure Cosmos DB, managed Kubernetes) are convenient but are not vendor agnostic — they tie you to a specific cloud provider’s ecosystem, violating the second requirement. They also often run more services under the hood than a minimal microservices approach.
References
CompTIA Cloud+ (CV0-004) objectives: Cloud-native concepts, application design patterns, security best practices (minimal attack surface), and virtualization.
A company uses containers stored in Docker Hub to deploy workloads (or its laaS infrastructure. The development team releases changes to the containers several times per hour. Which of the following should a cloud engineer do to prevent the proprietary code from being exposed to third parties?
A. Use laC to deploy the laaS infrastructure.
B. Convert the containers to VMs.
C. Deploy the containers over SSH.
D. Use private repositories for the containers.
Explanation:
The company is storing containers in Docker Hub (a public container registry by default) and deploying them to IaaS infrastructure. The development team releases changes several times per hour, and the goal is to prevent proprietary code from being exposed to third parties.
D. Use private repositories for the containers.
Docker Hub (and other container registries) offers both public and private repositories.
✅ Private repositories ensure that container images are only accessible to authorized users and systems (e.g., the company’s IaaS environment, CI/CD pipeline, and authenticated developers)
✅ This directly addresses the risk of proprietary code exposure by restricting access
✅ Private repositories can be hosted on Docker Hub (paid plan), cloud provider registries (Amazon ECR, Azure Container Registry, Google Container Registry), or self-hosted registries
✅ This solution supports frequent updates (several times per hour) without exposing code to the public
Why the other options are incorrect:
A. Use IaC to deploy the IaaS infrastructure: Infrastructure as Code (IaC) such as Terraform or CloudFormation is used to provision and manage infrastructure consistently. While IaC is a best practice, it does not address the security concern of proprietary code being exposed in a public container registry. The images themselves remain public regardless of how infrastructure is deployed.
B. Convert the containers to VMs: Converting containers to virtual machines would change the deployment architecture and likely increase overhead, but it does not solve the exposure problem. If the VM images are stored in a public location or the code is otherwise exposed, the proprietary code remains at risk. Additionally, containers are well-suited for frequent updates; moving to VMs would reduce deployment velocity.
C. Deploy the containers over SSH: SSH (Secure Shell) is a protocol for secure remote access. While deploying containers over SSH might secure the transfer of images, it does not prevent proprietary code from being exposed if the images themselves are stored in a public repository. Anyone with access to Docker Hub could still pull the public images and inspect the code. This option addresses transport security, not repository access control.
Reference
CompTIA Cloud+ CV0-004 Exam Objectives:
Domain 5.0: Security
5.2: Given a scenario, apply security controls in a cloud environment. Includes access controls for container registries and the use of private repositories to protect proprietary code and intellectual property.
Domain 2.0: Deployment
2.2: Given a scenario, deploy cloud resources using containers. Covers container registry selection and security considerations (public vs. private).
| Page 6 out of 26 Pages |