Free CompTIA SK0-005 Practice Questions 2026 - Page 11

Topic 1: Exam Set A
A server administrator is installing a new server that uses 40G0 network connectivity. The administrator needs to find the proper cables to connect the server to the switch. Which of the following connectors should the administrator use?
A. SFP+
B. GBIC
C. SFP
D. QSFP+
Explanation
The critical detail in this scenario is the specification of 40G network connectivity, meaning 40 Gigabits per second. Selecting the proper physical connector is essential to achieve this designed speed, as using an incorrect transceiver will result in a failed link or a connection that operates at a much lower, suboptimal speed.
Why D is Correct (QSFP+):
QSFP+ stands for Quad Small Form-factor Pluggable Plus. This transceiver is the industry standard for 40 Gigabit Ethernet (40GbE).
The name provides the key to its functionality:
"Quad" means it aggregates four independent serial data channels, each typically running at 10 Gbps. By combining these four channels, the QSFP+ form factor achieves a total throughput of 40 Gbps. It is designed specifically for high-density, high-performance networking applications like connecting servers to top-of-rack switches in data centers. An administrator installing a 40G NIC would need to populate its ports with QSFP+ transceivers and use the appropriate cabling (e.g., a QSFP+ Direct Attach Copper cable or a QSFP+ fiber optic transceiver with LC fiber cables) to connect to a compatible 40G switch port.
Why the Other Options are Incorrect:
A. SFP+:
SFP+ (Enhanced Small Form-factor Pluggable) is an extremely common and reliable transceiver, but it is the standard for 10 Gigabit Ethernet (10GbE). While it is an evolution of the SFP form factor, it is not capable of the 40 Gbps data rate required in this scenario. Attempting to plug an SFP+ transceiver into a 40G QSFP+ port is physically impossible, as the form factors are different sizes. Using SFP+ would limit the connection to a maximum of 10 Gbps, wasting 75% of the server's potential network bandwidth.
B. GBIC:
GBIC (Gigabit Interface Converter) is a historical transceiver standard used for 1 Gigabit Ethernet (1GbE). It was largely superseded over a decade ago by the much smaller SFP form factor. GBICs are significantly larger than SFP, SFP+, or QSFP+ modules and are obsolete in modern data centers. They are completely incapable of 40 Gbps speeds and are not physically compatible with any modern 40G network interface card.
C. SFP:
The standard SFP (Small Form-factor Pluggable), sometimes called "mini-GBIC," is the successor to the GBIC and is used for 1 Gigabit Ethernet and, in some cases, Fiber Channel. Like the GBIC, it is functionally incapable of supporting a 40 Gbps connection. While it is still in use for many 1G applications, it would be a severe bottleneck for a server designed for 40G connectivity.
Reference
This question tests knowledge of physical hardware and networking standards, a core component of the CompTIA Server+ (SK0-005) exam objective:
1.1 Given a scenario, install physical hardware.
A server administrator must be proficient in identifying different transceiver form factors and their corresponding data rates to ensure compatibility and performance between servers, cables, and network switches. Understanding the progression from older standards like GBIC to modern ones like QSFP+ and the emerging QSFP28 (for 100GbE) is crucial for successful hardware installation and troubleshooting in a data center environment.
A server technician is installing a Windows server OS on a physical server. The specifications for the installation call for a 4TB data volume. To ensure the partition is available to the OS, the technician must verify the:
A. hardware is UEFI compliant
B. volume is formatted as GPT
C. volume is formatted as MBR
D. volume is spanned across multiple physical disk drives
Explanation:
When installing a Windows Server operating system and creating large storage volumes, it is important to understand the limitations of the partitioning schemes used to define how data is organized on the disk. The key point in this question is the 4TB data volume requirement.
Let’s examine the relevant partitioning standards:
MBR (Master Boot Record)
The MBR partitioning scheme is the older standard.
It supports a maximum partition size of 2TB.
Any space beyond 2TB on a disk cannot be addressed or used by the OS if MBR is used.
GPT (GUID Partition Table)
GPT is the modern standard that replaces MBR and supports disks larger than 2TB.
GPT can theoretically support volumes up to 9.4 zettabytes, far exceeding any current hardware limits.
GPT is also required for UEFI-based booting, but even in legacy BIOS systems, GPT can be used for data volumes (not boot volumes).
In this case, since the requirement is for a 4TB data volume, the disk must use GPT formatting. Otherwise, the system would only recognize up to 2TB of the disk.
Option Analysis:
A. Hardware is UEFI compliant – Incorrect
UEFI compliance is only required when booting from a GPT disk, not when using GPT for a data volume. The question specifies the volume is for data, not the boot partition.
B. Volume is formatted as GPT – Correct
GPT supports partitions larger than 2TB, making it the only suitable choice for a 4TB data volume.
C. Volume is formatted as MBR – Incorrect
MBR partitions are limited to 2TB; a 4TB disk would be partially unusable.
D. Volume is spanned across multiple physical disk drives – Incorrect
Spanning (using dynamic disks) can increase total storage, but it doesn’t address the partitioning limit that restricts how much space a single disk partition can handle.
Reference:
CompTIA Server+ (SK0-005) Exam Objectives, Domain 1.3: “Summarize storage solutions, concepts, and technologies.”
Microsoft Documentation: “Windows support for hard disks that are larger than 2 TB” (KB 2581408).
CompTIA Server+ Official Study Guide (Exam SK0-005), Chapter 4: Disk Partitioning and File Systems.
Summary:
To ensure the Windows Server OS can recognize and use the entire 4TB data volume, the technician must format the volume using the GPT partitioning scheme, since MBR cannot handle partitions larger than 2TB.
A very old PC is running a critical, proprietary application in MS-DOS. Administrators are concerned about the stability of this computer. Installation media has been lost, and the vendor is out of business. Which of the following would be the BEST course of action to preserve business continuity?
A. Perform scheduled chkdsk tests.
B. Purchase matching hardware and clone the disk.
C. Upgrade the hard disk to SSD.
D. Perform quarterly backups.
Explanation:
This scenario presents a classic "legacy system" problem with a high risk of business disruption. The system is old, relies on obsolete hardware, and cannot be recreated from installation media.
The Core Problem:
The single greatest point of failure here is the aging PC hardware itself. A mechanical hard drive is very likely to fail, and other components like the motherboard, CPU, or memory could fail at any time, rendering the critical application inaccessible forever.
The Solution's Rationale:
By purchasing matching (or as close as possible) hardware and cloning the existing disk, you are creating a ready-to-use, immediate replacement. If the original PC fails, you can simply connect the cloned disk to the new (old) hardware and boot up, minimizing downtime and preserving business continuity. This directly addresses the most imminent threat.
Why the other options are incorrect:
A. Perform scheduled chkdsk tests:
While chkdsk can help with filesystem integrity on a working system, it does nothing to protect against a complete hardware failure. It is a reactive maintenance tool, not a business continuity strategy. If the hard drive physically dies, chkdsk is useless.
C. Upgrade the hard disk to SSD:
While upgrading to an SSD might improve performance and reliability on that specific machine, it introduces new risks. MS-DOS and its drivers may not be compatible with an SSD's architecture or a modern disk controller. More importantly, this action only protects against a single point of failure (the old HDD) but not against the failure of the motherboard, power supply, or other critical components.
D. Perform quarterly backups:
Backups are a fundamental part of any disaster recovery plan. However, in this specific case, a backup alone is insufficient. If the original hardware fails, you would have a backup image but no way to restore it to a compatible system. Without the installation media or vendor support, restoring a backup to dissimilar hardware is often impossible, especially with an operating system as old as MS-DOS.
Reference
This question falls under Domain 4.0: Disaster Recovery.
4.1: Explain disaster recovery concepts.
4.2: Carry out appropriate backup and restore procedures.
The key concept tested here is the difference between backup (having a copy of the data/OS) and recovery (the ability to actually restore operations). Option B is the only one that provides a full recovery solution by ensuring you have both the data (via the clone) and the compatible hardware required to run it.
A storage administrator is investigating an issue with a failed hard drive. A technician replaced the drive in the storage array; however, there is still an issue with the logical volume. Which of the following best describes the NEXT step that should be completed to restore the volume?
A. Initialize the volume
B. Format the volume
C. Replace the volume
D. Rebuild the volume
Explanation:
When a hard drive in a storage array fails, the array enters a degraded state, meaning data redundancy is lost until the failed drive is replaced and the volume is restored. After the technician installs a new replacement drive, the next critical step is to rebuild the volume. The rebuild process reconstructs the lost data from the remaining drives using parity (in RAID 5 or 6) or mirrored data (in RAID 1 or 10) to repopulate the new disk with accurate data. This operation restores full redundancy and normal functionality to the logical volume.
The rebuild process typically runs automatically in many modern RAID controllers, but sometimes it must be initiated manually through the RAID management utility or storage array console. Depending on the size of the disks and the RAID level, the rebuild can take from several hours to more than a day. During this period, the array remains in a vulnerable state, so it’s best practice to monitor the rebuild closely and avoid heavy workloads until it is complete.
Why the other options are incorrect:
A. Initialize the volume:
Initialization is a process that prepares a new disk or array for use by clearing all data and creating new structures. Doing this on an existing logical volume would erase data and destroy the existing configuration, making recovery impossible.
B. Format the volume:
Formatting creates a file system (such as NTFS, ext4, or FAT32) on a disk or partition, which would overwrite existing data. This step is only necessary when setting up new storage, not when restoring a RAID array.
C. Replace the volume:
The logical volume does not need replacement; the failed physical disk has already been replaced. Replacing the entire volume would result in total data loss.
References:
CompTIA Server+ (SK0-005) Exam Objectives, Domain 3.3 – “Given a scenario, perform appropriate RAID configuration and maintenance.”
CompTIA Server+ Study Guide (SK0-005), Chapter on Storage Solutions and RAID Management – covers steps for drive replacement and array rebuild.
Dell EMC and HPE RAID Controller Administration Guides – both recommend initiating a rebuild after replacing a failed drive to restore redundancy and data integrity.
When configuring networking on a VM, which of the following methods would allow multiple VMs to share the same host IP address?
A. Bridged
B. NAT
C. Host only
D. vSwitch
Explanation
Network Address Translation (NAT) is the method used in virtualization environments that allows multiple Virtual Machines (VMs) to share the host computer's single public or external IP address when communicating with the outside network (like the internet).
Here is a breakdown of why:
NAT's Function:
NAT acts like a router for the virtual machines.2 It assigns each VM a private IP address on an internal, hidden virtual subnet (e.g., $192.168.x.x$). When a VM sends a packet out, the host intercepts it, performs address translation, and replaces the VM's private IP with the host's physical IP address before sending it to the external network.
IP Conservation/Sharing:
Because the external network only ever sees the host's IP address, all VMs can effectively share that one address. The host maintains a translation table (like a home router) to track which incoming packets should be routed back to which specific internal VM and port.
Isolation:
This method provides a layer of isolation, as the VMs are not directly addressable from the external network without specific port forwarding rules.
Why the Other Options are Incorrect
A. Bridged:
In Bridged mode, the VM connects directly to the physical network (via the host's physical NIC). The VM is treated as a separate, full-fledged device on the network and requests its own unique IP address from the external DHCP server. It does not share the host's IP address.
C. Host only:
Host-only networking creates a private, isolated network strictly between the VM(s) and the host machine. The VMs can communicate with the host and each other, but they have no direct access to the external network, making the question of sharing the host's external IP irrelevant.
D. vSwitch (Virtual Switch):
The vSwitch is the software component (Layer 2 device) that facilitates all VM networking traffic. It is the virtual infrastructure that supports the networking modes (NAT, Bridged, Host-Only), but it is not the method of IP sharing itself.
Reference
This question directly relates to CompTIA Server+ (SK0-005) Objective 2.2: Summarize networking concepts and services specifically the virtualization sub-topic concerning networking types (Bridged, NAT, Host-Only). Understanding how these modes handle IP addressing and external connectivity is essential for managing virtual server environments.
A snapshot is a feature that can be used in hypervisors to:
A. roll back firmware updates.
B. restore to a previous version.
C. roll back application drivers.
D. perform a backup restore.
Explanation:
A snapshot in a virtualized environment is a point-in-time capture of the state, data, and configuration of a virtual machine (VM). It is a feature provided by the hypervisor (like VMware vSphere, Microsoft Hyper-V, or Citrix Hypervisor).
What a Snapshot Captures: A snapshot typically includes:
The VM's memory state (what was in RAM at that moment).
The VM's settings and configuration.
The state of all the VM's virtual disks.
Primary Purpose:
The primary use of a snapshot is to return the VM to the exact state it was in when the snapshot was taken. This is invaluable before making a potentially risky change, such as installing new software, applying a patch, or editing the registry. If the change causes problems, you can instantly "restore to a previous version" of the entire VM by reverting to the snapshot.
Why the other options are incorrect:
A. roll back firmware updates:
Firmware updates are typically applied to the physical hardware or the hypervisor itself, not within a VM. A VM snapshot does not capture the state of the physical host's firmware. It is isolated to the virtual machine's environment.
C. roll back application drivers:
While reverting a snapshot would indeed roll back driver changes that were made inside the VM after the snapshot was taken, this is too narrow. The snapshot doesn't just roll back drivers; it rolls back the entire system state to a previous point. Option B is a more comprehensive and accurate description of the snapshot's function.
D. perform a backup restore:
This is a critical distinction. A snapshot is not a backup. Snapshots are stored on the same primary storage as the live VM and have performance and storage implications if left in place for a long time. A true backup is a separate, redundant copy of the data, often on different media, designed for long-term retention and recovery from a catastrophic failure. While reverting a snapshot feels like a "restore," it is a fundamentally different operation with different goals and risks.
Reference
This question aligns with Domain 3.0: Server Maintenance and Domain 4.0: Disaster Recovery.
3.3: Explain the purpose of asset management and documentation. (Using snapshots before changes is a key part of change management documentation).
4.2: Carry out appropriate backup and restore procedures. (It's crucial to understand that a snapshot is a convenience feature for quick reversion, not a substitute for a formal backup strategy).
In summary, a snapshot is a hypervisor feature designed to quickly and easily restore a virtual machine to a previous point in time, making option B the most accurate and complete answer.
A systems administrator deployed a new web proxy server onto the network. The proxy
server has two interfaces: the first is connected to an internal corporate firewall, and the
second is connected to an internet-facing firewall. Many users at the company are reporting
they are unable to access the Internet since the new proxy was introduced. Analyze the
network diagram and the proxy server’s host routing table to resolve the Internet
connectivity issues.
INSTRUCTIONS
Perform the following steps:
1. Click on the proxy server to display its routing table.
2. Modify the appropriate route entries to resolve the Internet connectivity issue.
If at any time you would like to bring back the initial state of the simulation, please click the
Reset All button.
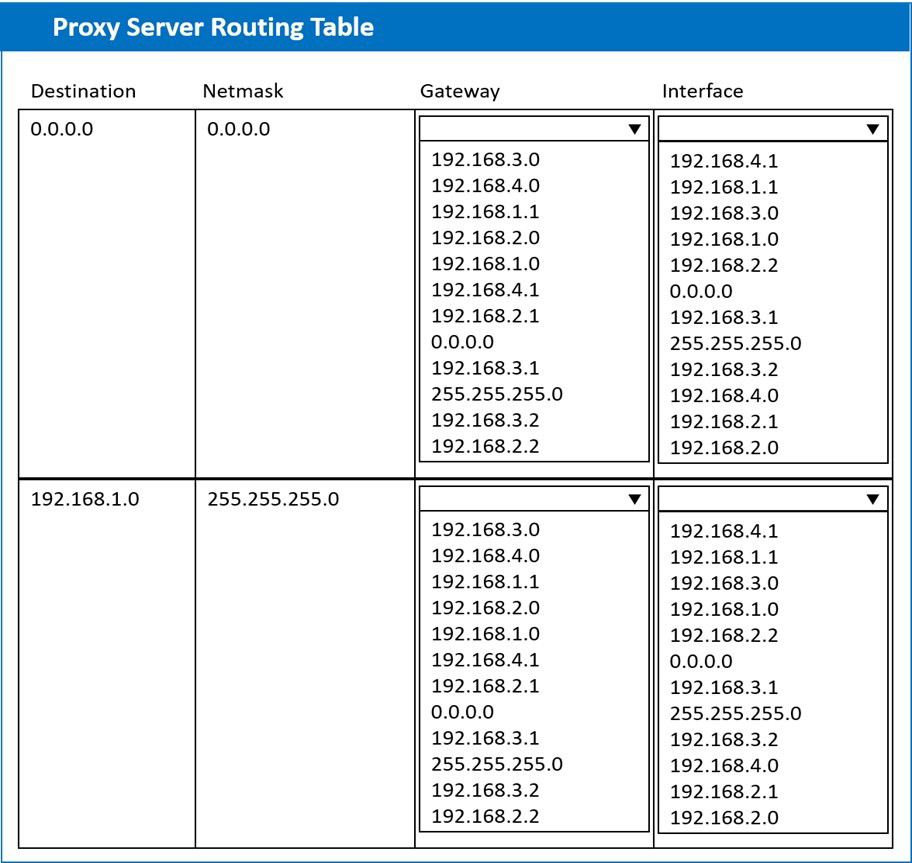
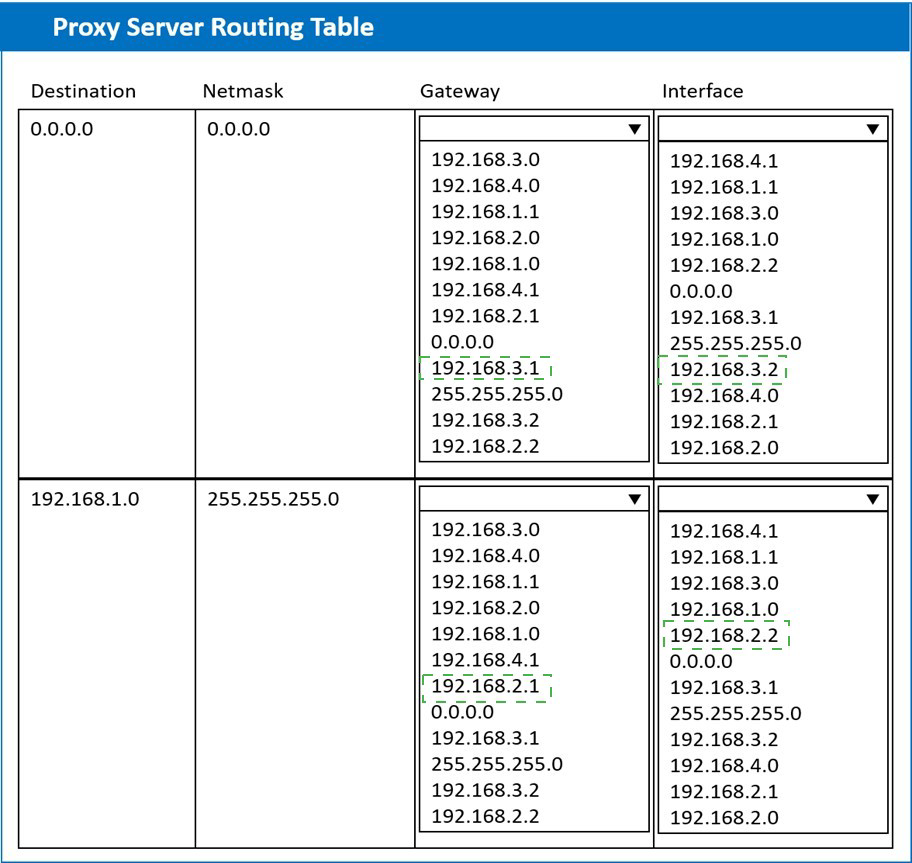
A technician has been asked to check on a SAN. Upon arrival, the technician notices the red LED indicator shows a disk has failed. Which of the following should the technician do NEXT, given the disk is hot swappable?
A. Stop sharing the volume
B. Replace the disk
C. Shut down the SAN
D. Stop all connections to the volume
Explanation:
When a red LED indicator appears on a disk in a Storage Area Network (SAN), it typically signals a hardware failure or that the drive is no longer operational. Since the disk is identified as hot swappable, the technician can safely replace it without shutting down the SAN or disconnecting clients. The next appropriate step is to replace the failed disk with an identical or compatible model. Once installed, the RAID controller or SAN management software will automatically recognize the new drive and begin the rebuild process to restore redundancy and data integrity.
Before removing the failed disk, the technician should verify the drive’s failure in the SAN’s management interface to ensure the correct unit is replaced. Modern SAN systems often have indicators, such as LED lights or alerts in the management dashboard, that show which disk has failed. After replacement, the rebuild process should be closely monitored to ensure it completes successfully and the array returns to an optimal state. Depending on the RAID level and data size, the rebuild process can take several hours. During this time, the SAN may experience slightly reduced performance but will remain online.
Why the other options are incorrect:
A. Stop sharing the volume:
This is not required since SANs are designed for continuous availability, even during hardware maintenance. Stopping the volume would unnecessarily disrupt users and applications.
C. Shut down the SAN:
Shutting down the SAN would cause total service interruption and negates the advantage of having hot-swappable components. This should only be done if the hardware or RAID controller does not support hot-swap functionality.
D. Stop all connections to the volume:
Disconnecting clients is unnecessary because most enterprise SANs maintain data access during disk replacement and rebuilding. Doing so would lead to avoidable downtime.
References:
CompTIA Server+ (SK0-005) Exam Objectives, Domain 3.3 – “Given a scenario, perform appropriate RAID configuration and maintenance.”
CompTIA Server+ Study Guide, Chapter on Storage Management and RAID Maintenance.
Dell EMC PowerVault and HPE MSA SAN Administration Guides – sections on Hot-Swap Drive Replacement and RAID Rebuild Monitoring.
A systems administrator is preparing to install two servers in a single rack. The administrator is concerned that having both servers in one rack will increase the chance of power issues due to the increased load. Which of the following should the administrator implement FIRST to address the issue?
A. Separate circuits
B. An uninterruptible power supply
C. Increased PDU capacity
D. Redundant power supplies
Explanation
The administrator's primary concern is that the increased load from adding a second server might cause power issues, which typically means tripping a circuit breaker or overloading the Power Distribution Unit (PDU).
Identify the Root Cause:
The concern is about the total power draw of the equipment exceeding the available capacity on the current circuit/PDU.
Server 1 Load + Server 2 Load >
Current PDU Capacity.
Required First Step:
To manage an increase in load, the administrator must first ensure the distribution equipment (the PDU) can handle the total maximum load of all devices in the rack.
Implementing a PDU with a higher capacity (C) directly addresses the concern about the increased load and prevents immediate tripping/overload. You must have the capacity before you worry about redundancy.
Why Others are Secondary or Address Redundancy, Not Load:
A. Separate circuits and D. Redundant power supplies are crucial for High Availability (HA) and Redundancy (protecting against a single point of failure), but they don't solve the core problem of insufficient total capacity if the overall load exceeds the maximum rating of the existing PDU or the breaker it is connected to. You need enough power first.
B. An uninterruptible power supply (UPS) provides protection against power loss (outages, brownouts) and conditioning (surges, noise). While important, it is the next step for availability, not the first step for safely accommodating an increased load in the rack.
In a logical sequence:
Capacity (PDU) > Redundancy (Separate Circuits/PSUs) > Conditioning/Availability (UPS).
Reference
This question relates to CompTIA Server+ (SK0-005) Objective 1.1: Install Physical Hardware which includes topics on racking servers, managing power, and power cabling. A fundamental aspect of server installation is correctly calculating and managing the power requirements and ensuring the Power Distribution Unit (PDU) is rated to handle the aggregated maximum (plate) load of all connected equipment with a safety buffer (typically not exceeding 80% of the rated capacity).
Which of the following would be BEST to help protect an organization against social engineering?
A. More complex passwords
B. Recurring training and support
C. Single sign-on
D. An updated code of conduct to enforce social media
Explanation:
Social engineering is a psychological attack, not a technical one. It relies on manipulating people into breaking normal security procedures. Attackers use tactics like pretexting, phishing, baiting, and tailgating to trick employees into revealing sensitive information, granting access, or performing actions that compromise security.
Addressing the Human Firewall:
The only truly effective defense against social engineering is a well-trained, vigilant, and supported workforce. Recurring training ensures that employees are:
Aware of the latest social engineering tactics.
Able to recognize suspicious requests, emails, or phone calls.
Empowered to report potential incidents.
Reinforced in their knowledge over time, as a one-time training is easily forgotten.
Why the other options are incorrect:
A. More complex passwords:
Complex passwords are a strong defense against technical attacks like brute-forcing. However, a social engineer can simply trick a user into voluntarily giving away their complex password. This measure does not address the human element of the attack.
C. Single sign-on (SSO):
SSO is a convenience and access management tool that reduces the number of passwords users must remember. While it can improve security by ensuring better password hygiene, it does not protect against social engineering. In fact, if an attacker socially engineers a user's SSO credentials, they gain access to all integrated applications.
D. An updated code of conduct to enforce social media:
While a social media policy is a good component of a broader security program, it is a policy, not a proactive defense. It sets rules but does not actively train employees to recognize and resist manipulation. A policy alone is insufficient without the ongoing training and support to make it effective.
Reference
This question falls under Domain 5.0: Security.
5.2: Summarize security concepts.
5.5: Explain data security risks and mitigation strategies.
The key principle tested here is that people are often the weakest link in security. The most robust technical controls can be bypassed by manipulating a single person. Therefore, the "BEST" protection is a continuous effort to strengthen that human element through recurring training and support.
| Page 11 out of 50 Pages |