CompTIA SK0-005 Practice Test 2026
Updated On : 8-Jul-2026Prepare smarter and boost your chances of success with our CompTIA SK0-005 practice test 2026. These CompTIA Server+ Certification test questions helps you assess your knowledge, pinpoint strengths, and target areas for improvement. Surveys and user data from multiple platforms show that individuals who use SK0-005 practice exam are 40–50% more likely to pass on their first attempt.
Start practicing today and take the fast track to becoming CompTIA SK0-005 certified.
14930 already prepared
493 Questions
CompTIA Server+ Certification
4.8/5.0

Topic 3, Exam Set C
A server technician is placing a newly configured server into a corporate environment. The
server will be used by members of the accounting department, who are currently assigned
by the VLAN identified below:
Which of the following IP address configurations should the technician assign to the new
server so the members of the accounting group can access the server?
A. IP address: 172.16.25.90/24 Default gateway: 172.16.25.254
B. IP address: 172.16.25.101/16 Default gateway: 172.16.25.254
C. IP address: 172.16.25.254/24 Default gateway: 172.16.25.1
D. IP address: 172.16.26.101/24 Default gateway: 172.16.25.254
Explanation:
To ensure members of the accounting department can access the server, the server must be placed on the same subnet/VLAN as their devices. A subnet mask of /24 corresponds to the network 172.16.25.0 – 172.16.25.255, which allows devices to communicate directly without routing. The IP address 172.16.25.90 falls within this valid network range, and the chosen default gateway 172.16.25.254 is a typical router address for that subnet. This configuration ensures seamless communication within the VLAN and proper routing outside the network if needed.
Why Other Options Are Incorrect
B. 172.16.25.101/16 | Gateway: 172.16.25.254
A /16 mask (255.255.0.0) places the server in a much larger network: 172.16.0.0 – 172.16.255.255. Although the IP is in the same numerical range, this subnet would not match the VLAN configuration used by accounting. Mismatched subnet masks cause devices to interpret different network boundaries, resulting in inconsistent connectivity or failed local communication.
C. 172.16.25.254/24 | Gateway: 172.16.25.1
The IP 172.16.25.254 is typically used as the subnet’s default gateway address or a reserved network boundary value, and should not be assigned to a server. Additionally, the proposed default gateway 172.16.25.1 does not align with common gateway assignments on this VLAN, leading to routing failures and no external communication.
D. 172.16.26.101/24 | Gateway: 172.16.25.254
The IP address is in a different network entirely (172.16.26.0/24). Devices on 172.16.25.0/24 would treat it as a remote subnet, requiring routing even for local access. This breaks direct communication with accounting department users and would prevent access without proper routing rules, which are not indicated.
Reference
Devices must share the same IP network range, subnet mask, and VLAN to communicate directly. The default gateway must be within the same subnet and typically uses the highest usable address for structured network design.
Practical Networking Tip
When deploying a new server:
Confirm assigned VLAN and subnet mask from network documentation
Choose an unused static IP inside the correct VLAN range
Use the proper gateway defined for that subnet
Verify connectivity using ping to local hosts, then gateway, then external networks
A technician needs to restore data from a backup. The technician has these files in the
backup inventory: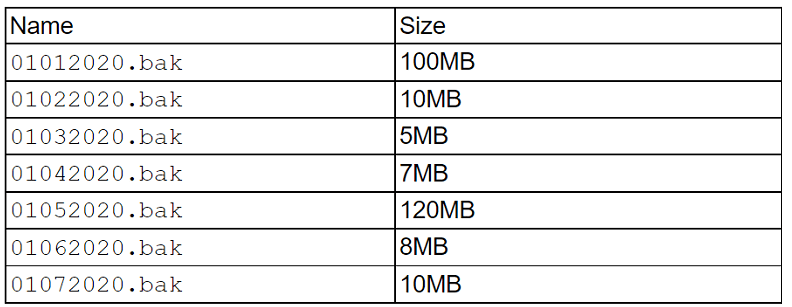
Which of the following backup types is being used if the file 01062020.bak requires another
file to restore data?
A. Full
B. Incremental
C. Snapshot
D. Differential
Explanation
The backup type being used is B. Incremental because it requires another file (specifically, the last full backup and potentially other incremental files) to fully restore the data.
An Incremental backup only captures the data that has changed since the last backup of any type (either a full backup or the previous incremental backup).
Because each incremental file (like 01062020.bak) contains only a small "slice" of the changes, it cannot be used alone to restore the entire system or dataset to the point in time it was taken.
Restoration from an incremental backup set requires the initial full backup (the base) PLUS all subsequent incremental backups applied sequentially, up to the desired restore point. This is why the technician noted that 01062020.bak "requires another file to restore data."
Incorrect Options
A. Full
A Full backup contains a complete copy of all the data at the time it was created. It is the only backup type that can be restored entirely on its own, without requiring any other backup files.
C. Snapshot
A Snapshot is a point-in-time reference (like a freeze-frame) of a virtual machine or a volume's file system, typically storing only the differences from the base image. While a snapshot is dependent on a base image, it is a feature of virtual environments or file systems (like ZFS) and not a traditional file-based backup type that fits the .bak extension and the described dependency chain as closely as an incremental backup does.
D. Differential
A Differential backup is dependent on another file, but only one other file:
the last full backup. A differential backup captures all changes since the last full backup.
To restore from a differential set, you only need the most recent full backup and the most recent differential backup. It does not require all previous differential or incremental files, unlike the incremental method.
| Page 1 out of 50 Pages |
CompTIA Server+ Certification Practice Questions
CompTIA Server+ SK0-005 Official Exam Blueprint And Our Practice Questions
| CompTIA Server+ SK0-005 Domain | Official Exam Weight | Our Practice Questions |
|---|---|---|
| Server Hardware Installation and Management | 18% | 60 |
| Our Practice Questions Covers Subtopics: Server hardware installation, RAID configurations, Storage technologies, Power supplies, Cooling systems, BIOS and UEFI, Firmware updates, Physical server maintenance, Rack installation, Cabling standards, CPU architecture, Memory installation, Expansion cards, Peripheral devices, Hardware compatibility, Asset management | ||
| Server Administration | 30% | 147 |
| Our Practice Questions Covers Subtopics: Server operating systems, User and group management, Virtualization, Cloud computing, Network configuration, DNS and DHCP, Active Directory, Group policies, Storage management, Backup management, Monitoring tools, Performance optimization, Resource allocation, Patch management, Service configuration | ||
| Security and Disaster Recovery | 24% | 73 |
| Our Practice Questions Covers Subtopics: Server security, Access controls, Authentication methods, Encryption, Firewall configuration, Physical security, Disaster recovery planning, Business continuity, Backup strategies, High availability, Fault tolerance, Risk management, Security policies, Compliance requirements, Incident response, Vulnerability mitigation | ||
| Troubleshooting | 28% | 213 |
| Our Practice Questions Covers Subtopics: Troubleshooting methodology, Hardware failures, Boot issues, Storage failures, RAID troubleshooting, Network connectivity issues, Virtualization troubleshooting, Performance bottlenecks, Service failures, Power issues, Cooling problems, Log analysis, Diagnostic tools, System recovery, Security troubleshooting, Disaster recovery testing, Backup restoration, Server performance analysis | ||
Server hardware, storage, security, and disaster recovery—this exam covers it all. This practice test targets the SK0-005 objectives, including server administration, troubleshooting, and virtualization. You will face questions on RAID configurations, power management, network cabling, and server hardening techniques. Each scenario tests your ability to apply concepts to real data center situations. The detailed explanations turn every practice attempt into a learning opportunity. Whether you are weak on storage technologies or failover clustering, this test reveals your gaps. Prepare smarter for certification day and validate your server expertise with confidence.
Our Happy Customers
Server administration requires deep knowledge of hardware, storage, and virtualization. Preptia SK0-005 exam questions covered everything from RAID configurations to server hardening. I felt completely prepared and passed on my first attempt. Highly recommended for server admins!
David Chen, Systems Administrator | Boston, MA
Server management concepts were clearly explained through the Preptia.com Server+ SK0-005 mock exam. The questions covered server hardware, virtualization, and maintenance tasks thoroughly.
Miguel Herrera | Mexico