Free CompTIA CS0-003 Practice Questions 2026 - Page 5

An organization has tracked several incidents that are listed in the following table:

Which of thefollowing is the organization's MTTD?
A. 140
B. 150
C. 160
D. 180
Explanation:
The question asks for the organization’s Mean Time to Detect (MTTD) based on a table of incidents, with options of 140, 150, 160, or 180 (presumably in minutes). MTTD is the average time from when a security incident occurs (e.g., a compromise) to when it is detected by the security team. However, the incident table referenced in the question is not provided, making it impossible to calculate the exact MTTD or select the correct answer. For the CS0-003 exam’s Incident Response and Management (Domain 3) and Security Operations (Domain 1) objectives, I’ll outline how to calculate MTTD and evaluate the options based on typical incident data analysis.
How to Calculate MTTD
Definition: MTTD is the average time taken to detect incidents across a set of events. It’s calculated as:
Sum the detection times for all incidents (time from compromise to detection).
Divide by the number of incidents.
Formula: MTTD = Σ(Detection Time - Compromise Time) / Number of Incidents.
Required Data: The incident table would typically include:
Compromise Time: When each incident occurred (e.g., unauthorized login, malware execution).
Detection Time: When the security team was alerted (e.g., via SIEM, IDS, or user report).
Incident Count: The number of incidents listed.
Example:
Incident 1: Compromise at 10:00 AM, detected at 10:30 AM (30 minutes).
Incident 2: Compromise at 11:00 AM, detected at 12:20 PM (80 minutes).
Incident 3: Compromise at 1:00 PM, detected at 4:00 PM (180 minutes).
MTTD = (30 + 80 + 180) / 3 = 290 / 3 ≈ 96.67 minutes.
CS0-003 Context: The exam tests incident response metrics like MTTD, often through performance-based questions (PBQs) requiring analysis of logs or incident timelines to calculate averages.
Why No Option Can Be Selected:
Missing Table: The question references a table of incidents, but without specific data (e.g., compromise and detection timestamps for each incident), the MTTD cannot be computed.
Options (140, 150, 160, 180): These are likely in minutes, but without the table, we can’t determine which matches the calculated MTTD.
For example:
If the table listed 3 incidents with detection times of 120, 150, and 150 minutes, MTTD = (120 + 150 + 150) / 3 = 140 minutes (option A).
Without data, all options (140, 150, 160, 180) are equally plausible or implausible.
Evaluating Each Option:
A. 140
Reason: Could be correct if the table shows incidents with an average detection time of 140 minutes, but no data confirms this.
B. 150
Reason: Possible if the average detection time across incidents is 150 minutes, but the lack of table data prevents verification.
C. 160
Reason: Would require the table to show an average detection time of 160 minutes, but no evidence supports this.
D. 180
Reason: Could be correct if the incidents average 180 minutes to detect, but without the table, this cannot be confirmed.
Incident Analysis Process:
Steps:
Extract Timestamps: From the table, note the compromise time and detection time for each incident.
Calculate Differences: Subtract compromise time from detection time for each incident.
Compute Average: Sum the differences and divide by the number of incidents.
Compare to Options: Match the calculated MTTD to the closest option (140, 150, 160, or 180).
Reference:
CompTIA CySA+ (CS0-003) Exam Objectives, Domains 1 (Security Operations) and 3 (Incident Response and Management), www.comptia.org, covering incident response metrics like MTTD.
CompTIA CySA+ Study Guide: Exam CS0-003 by Chapple and Seidl, discussing how to calculate MTTD from incident data.
A healthcare organization must develop an action plan based on the findings from a risk
assessment. The action plan must consist of:
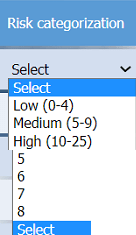
· Risk categorization
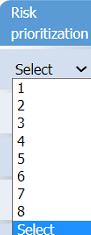
· Risk prioritization
. Implementation of controls
INSTRUCTIONS
Click on the audit report, risk matrix, and SLA expectations documents to review their
contents.
On the Risk categorization tab, determine the order in which the findings must be
prioritized for remediation according to the risk rating score. Then, assign a categorization
to each risk.
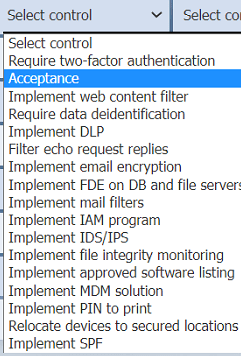
On the Controls tab, select the appropriate control(s) to implement for each risk finding.
Findings may have more than one control implemented. Some controls may be used
more than once or not at all.
If at any time you would like to bring back the initial state of the simulation, please click
the Reset All button.


Without access to the specific documents (Audit Report, Risk Matrix, SLA Expectations) or tabs (Risk Categorization, Controls), a definitive answer cannot be provided. However, I’ll outline the process a security analyst would follow to develop an action plan for a healthcare organization based on a risk assessment, addressing Risk Categorization, Risk Prioritization, and Implementation of Controls. This aligns with the CS0-003 exam’s Vulnerability Management (Domain 2), Security Operations (Domain 1), and Reporting and Communication (Domain 4) objectives, which emphasize risk assessment and mitigation strategies.
General Approach to Developing the Action Plan:
The task involves reviewing risk assessment findings, prioritizing them based on risk rating scores, categorizing risks, and selecting appropriate controls, tailored to a healthcare organization’s context (e.g., HIPAA compliance). Since the documents and tabs are not provided, I’ll describe the standard process and provide a hypothetical example to illustrate how to address the requirements.
Step 1: Risk Categorization
Objective: Assign each finding a risk category based on its nature and impact, typically aligned with frameworks like NIST SP 800-53 or HIPAA requirements.
Process:
Review Findings: Examine the Audit Report for vulnerabilities or risks (e.g., unpatched systems, weak authentication, data exposure)
Assign Categories: Common categories in healthcare include:
Confidentiality: Risks to patient data privacy (e.g., unprotected PII/PHI).
Integrity: Risks to data accuracy (e.g., unauthorized modifications).
Availability: Risks to system uptime (e.g., DoS vulnerabilities).
Compliance: Risks violating regulations (e.g., HIPAA non-compliance).
Finding: “Outdated EHR software” → Category: Compliance/Availability.
Finding: “Weak MFA on VPN” → Category: Confidentiality/Integrity.
CS0-003 Alignment: Domain 2 emphasizes categorizing risks based on assessment findings to align with organizational priorities and compliance needs.
Step 2: Risk Prioritization
Objective: Order findings for remediation based on risk rating scores, typically derived from the Risk Matrix and SLA Expectations.
Process:
Risk Rating Scores: Use the Risk Matrix to assign scores (e.g., CVSS scores, qualitative ratings like High/Medium/Low, or numerical scales like 1–100) based on:
Likelihood: Probability of exploitation (e.g., public exploit available).
Impact: Severity of consequences (e.g., PHI exposure, system downtime).
SLA Expectations: Prioritize based on remediation timelines (e.g., Critical risks within 7 days, High within 14 days, Medium within 30 days).
Order Findings: Sort from highest to lowest risk score, prioritizing Critical/High risks for remediation within SLA timelines.
Example:
Finding 1: “Unencrypted PHI” (CVSS 9.8, Critical) → Priority 1.
Finding 2: “Outdated EHR software” (CVSS 7.5, High) → Priority 2.
Finding 3: “Weak MFA on VPN” (CVSS 5.0, Medium) → Priority 3.
Finding 4: “Unnecessary open port” (CVSS 3.0, Low) → Priority 4.
CS0-003 Alignment: Domain 2 tests prioritizing vulnerabilities based on risk scores and organizational policies, often in performance-based questions (PBQs).
Step 3: Implementation of Controls
Objective: Select appropriate controls for each risk finding, with some findings requiring multiple controls and some controls reused across findings.
Process:
Review Findings: Match controls to the nature of each risk, considering healthcare requirements (e.g., HIPAA, NIST).
Available Controls: Common controls include:
Technical: Encryption, patching, MFA, firewalls, IDS/IPS, WAF.
Administrative: Policies, training, access reviews.
Physical: Secure server rooms, badge access.
Select Controls: Choose based on effectiveness, feasibility, and compliance. Multiple controls may apply to a single finding; some controls may be reused.
Example:
Finding 1: Unencrypted PHI
Controls: Enable AES-256 encryption for data at rest, deploy DLP to monitor data exfiltration.
Finding 2: Outdated EHR software
Controls: Apply vendor patches, implement WAF to mitigate exploits.
Finding 3: Weak MFA on VPN
Controls: Enforce strong MFA (e.g., token-based), update access policies.
Finding 4: Unnecessary open port
Controls: Configure firewall to close port, conduct regular port scans.
CS0-003 Alignment: Domains 1 and 2 emphasize selecting and implementing controls to mitigate risks, ensuring compliance and security.
Hypothetical Example:
Assume the Audit Report lists:
Finding 1: Unencrypted PHI on database server (CVSS 9.8, Critical).
Finding 2: Outdated web server software (CVSS 7.5, High).
Finding 3: Weak password policies (CVSS 5.5, Medium).
Finding 4: Open port 23 (Telnet) (CVSS 4.0, Medium).
Risk Categorization:
Finding 1: Confidentiality/Compliance (exposes PHI, violates HIPAA).
Finding 2: Availability/Compliance (exploitable software risks downtime).
Finding 3: Confidentiality/Integrity (weak passwords risk unauthorized access).
Finding 4: Confidentiality (Telnet is unencrypted, risks data interception).
Risk Prioritization:
Order: Finding 1 (Critical, CVSS 9.8) → Finding 2 (High, CVSS 7.5) → Finding 3 (Medium, CVSS 5.5) → Finding 4 (Medium, CVSS 4.0).
SLA: Critical (7 days), High (14 days), Medium (30 days).
Controls:
Finding 1: Encryption (AES-256), DLP deployment, access controls.
Finding 2: Patch management, WAF configuration.
Finding 3: Password policy enforcement, MFA implementation.
Finding 4: Firewall rule to close port 23, network monitoring.
Why No Definitive Answer:
Missing Documents: The question references an Audit Report, Risk Matrix, and SLA Expectations, but these are not provided, preventing specific categorization, prioritization, or control selection.
Tabs Unavailable: The Risk Categorization and Controls tabs are not accessible, so I cannot assign specific categories or controls to findings.
Options Implied: The task implies a PBQ where findings are listed with risk scores, and controls are selected from a list, but without data, I can only describe the process.
Reference:
CompTIA CySA+ (CS0-003) Exam Objectives, Domains 1 (Security Operations), 2 (Vulnerability Management), and 4 (Reporting and Communication), www.comptia.org, covering risk assessment, prioritization, and control implementation.
CompTIA CySA+ Study Guide: Exam CS0-003 by Chapple and Seidl, discussing risk management and mitigation in healthcare environments.
| Page 5 out of 50 Pages |